Sumo Logic App for PostgreSQL

The Sumo Logic App for PostgreSQL is a unified logs and metrics app for monitoring your PostgreSQL database. The app provides operational insights into the PostgreSQL database—installed on your local hardware—for real time analysis.
The Sumo Logic App for PostgreSQL includes predefined searches and dashboards that allow you to monitor logs and metrics for the database. The logs enable you to monitor database activity, user activity, incoming connections, query execution time, and errors. The metrics allow you to monitor database resource utilization and throughput performance.
This guide provides an overview of the Sumo App for PostgreSQL features and Dashboards, as well as instructions for collecting logs and metrics from PostgreSQL and installing the App.
PostgreSQL is an open source object-relational database that extends the robustness SQL language to safely store and scale extensive data workloads.
Sample Logs and Queries
{ "timestamp":1615988485842, "log":"2021-04-01 08:30:20.002 UTC [11916] postgres@postgres LOG: connection authorized: user=postgres database=postgres ", "stream":"stdout", "time":"2021-03-17T13:41:19.103646109Z" }
2021-04-01 08:30:20.002 UTC [11916] postgres@postgres LOG: connection authorized: user=postgres database=postgres
This sample Query is from the Fatal Errors panel of the PostgreSQL - Overview dashboard.
_sourceCategory=/PostgreSQL/* db_system=postgresql db_cluster={{db_cluster}}
| json auto maxdepth 1 nodrop
| if (isEmpty(log), _raw, log) as _raw
| parse "* * * [*] *@* *: *" as date,time,time_zone,thread_id,user,db,severity,msg
| where severity IN ("ERROR", "FATAL")
| count by date, time, severity, db, user, msg
Collecting Logs and Metrics from PostgreSQL
This section provides instructions for configuring log and metric collection for the Sumo Logic App for PostgreSQL. This app works for PostgreSQL database clusters running on PostgreSQL versions 11.x or 12.x.
Step 1: Configure Access
On your PostgreSQL database cluster, create a user that has access to following tables:
pg_stat_databasepg_stat_bgwriterpg_stat_replicationpg_databasepg_lockspg_stat_user_tablespg_stat_user_indexespg_statio_user_indexespg_statio_user_tablespg_class
Step 2: Configure Fields in Sumo Logic
Create the following Fields in Sumo Logic before configuring collection. This ensures that your logs and metrics are tagged with relevant metadata, which is required by the app dashboards. For information on setting up fields, see Sumo Logic Fields.
- Kubernetes environments
- Non-Kubernetes environments
If you're using PostgreSQL in a Kubernetes environment, create the fields:
pod_labels_componentpod_labels_environmentpod_labels_db_systempod_labels_db_cluster
If you're using PostgreSQL in a non-Kubernetes environment, create the fields:
componentenvironmentdb_systemdb_clusterpod
Step 3: Configure PostgreSQL Logs and Metrics Collection
Sumo Logic supports collection of logs and metrics data from PostgreSQL in both Kubernetes and non-Kubernetes environments. Click on the appropriate tab below based on the environment where your PostgreSQL clusters are hosted.
- Kubernetes environments
- Non-Kubernetes environments
In Kubernetes environments, we use the Telegraf Operator, which is packaged with our Kubernetes collection. You can learn more about it here. The diagram below illustrates how data is collected from PostgreSQL in Kubernetes environments. In the architecture shown below, there are four services that make up the metric collection pipeline: Telegraf, Prometheus, Fluentd and FluentBit.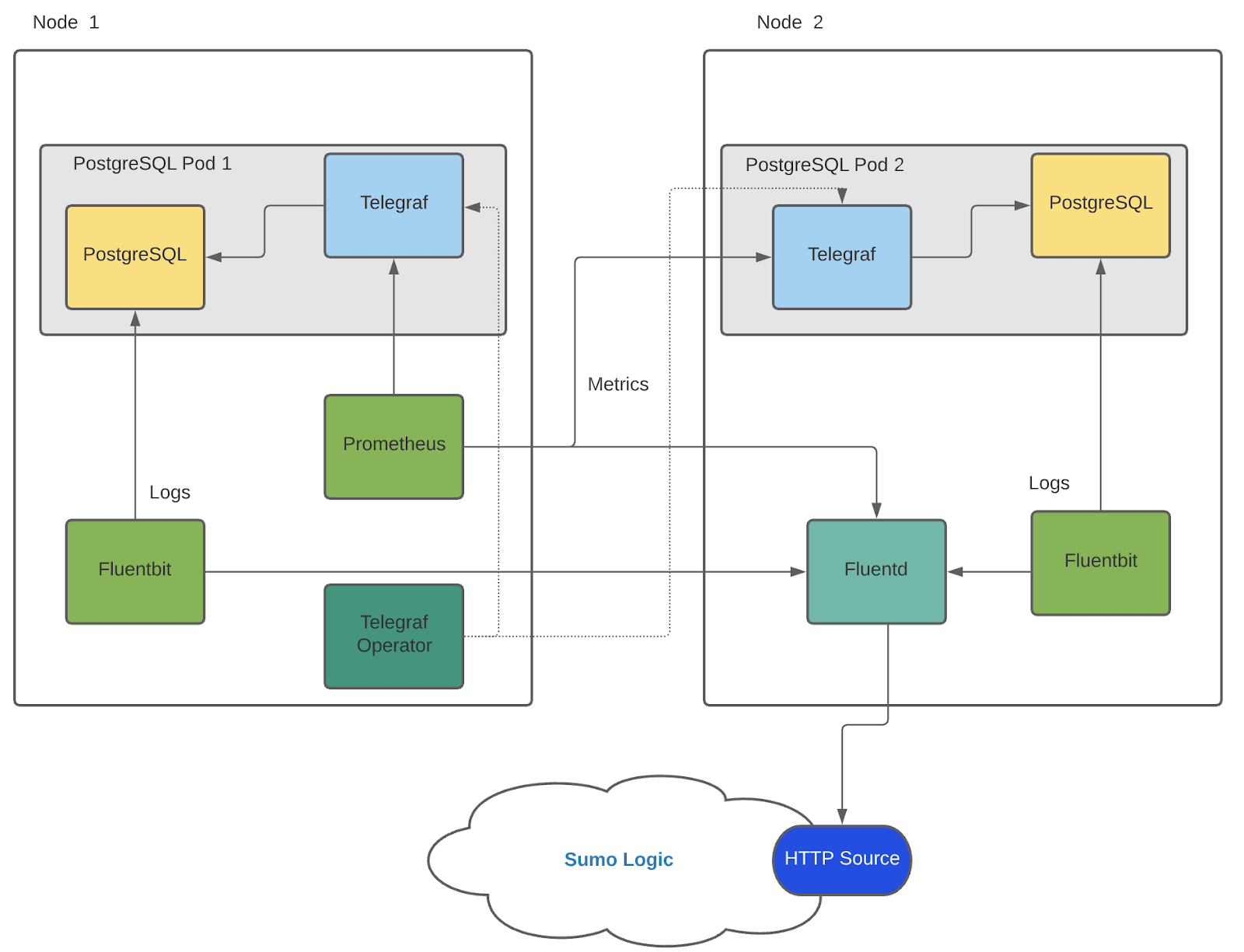
The first service in the pipeline is Telegraf. Telegraf collects metrics from PostgreSQL. Note that we’re running Telegraf in each pod we want to collect metrics from as a sidecar deployment: i.e. Telegraf runs in the same pod as the containers it monitors. Telegraf uses the PostgreSQL Extensible input plugin to obtain metrics, (For simplicity, the diagram doesn’t show the input plugins). The injection of the Telegraf sidecar container is done by the Telegraf Operator. Prometheus scrapes the metrics from each of the Telegraf containers and sends it to FluentD.We also have Fluentbit that collects logs written to standard out and forwards them to FluentD, which in turn sends all the logs and metrics data to a Sumo Logic HTTP Source.
Please ensure that you are monitoring your Kubernetes clusters with the Telegraf operator - If you are not, then please follow these instructions to do so.
Configure Metrics Collection
Follow the steps below to collect metrics from a Kubernetes environment:
- On your PostgreSQL Pods, add the following annotations mentioned in this file.
- Enter in values for the following annotation parameters (marked with
CHANGE_ME) in the downloaded file:telegraf.influxdata.com/inputs- This contains the required configuration for the Telegraf Postgres Input plugin. As telegraf will be run as a sidecar the host should always be localhost.- In the input plugins section which is
[[inputs.postgresql_extensible]]address- Specify the db user, db name and password used for connecting to the database. Examplehost=localhost user=postgres dbname=postgres password=mypassword sslmode=disable
- In the tags section, which is
[inputs.postgresql_extensible.tags]* `environment` - This is the deployment environment where the postgresql cluster resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.
* `db_cluster` - Enter a name to identify this PostgreSQL cluster. This cluster name will be shown in the Sumo Logic dashboards. For example: analytics-dbcluster, webapp-dbcluster.
* `db_cluster_address` - Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.
* `db_cluster_port` - Enter the database port. If not provided, a default port will be usednotedb_cluster_addressanddb_cluster_portshould reflect the exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields).
For example, if your application uses “postgresql-prod.sumologic.com:3306” as the connection string, the field values should be set as follows: db_cluster_address=postgresql-prod.sumologic.com db_cluster_port=3306.
If your application connects directly to a given postgresql node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration: host=postgresql-prod.sumologic.com
Pivoting to Tracing data from Entity Inspector is possible only for “PostgreSQL address” Entities. :::
- Do not modify the following values, as they will cause the Sumo Logic apps to not function correctly.
telegraf.influxdata.com/class: sumologic-prometheus- This instructs the Telegraf operator what output to use. This should not be changed.prometheus.io/scrape: "true"- This ensures our Prometheus plugin will scrape the metrics.prometheus.io/port: "9273"- This tells Prometheus what ports to scrape metrics from. This should not be changed.telegraf.influxdata.com/inputs- In the tags sections
[inputs.postgresql_extensible.tags] component= “database”- This value is used by Sumo Logic apps to identify application components.db_system= “postgresql”- This value identifies the database system.
- In the tags sections
- For more information on configuring the PostgreSQL input plugin for Telegraf, see this doc. For more information on all other Telegraf related global parameters, please see this doc.
- Once this has been done, the Sumo Logic Kubernetes collection will automatically start collecting metrics from the pods having the annotations defined in the previous step. Verify metrics are flowing into Sumo Logic by running the following metrics query.
component="database" and db_system="postgresql"
Collecting Metrics from Multiple Databases (Optional)
If you want to monitor multiple databases, copy and paste the text from this file, create another [[inputs.postgresql_extensible]] section, and add it in your annotations. This section contains only those queries which are meant to be run for each database. Click here for an example.
Configure Logs Collection
This section explains the steps to collect PostgreSQL logs from a Kubernetes environment.
Configuring logging parameters in postgresql.conf
- Edit the postgresql.conf configuration file present in your pod. Under the ERROR REPORTING AND LOGGING section of the file, use the following config parameters.
log_min_duration_statement = 250
log_connections = on
log_duration = on
log_hostname = on
log_timezone = 'UTC'
log_min_messages = 'WARNING'
log_line_prefix = '%m [%p] %q%u@%d '- For more information on the above parameters, see the PostgreSQL documentation.
- It’s recommended to save configurations in ConfigMap so that when pods are spawned/killed, the configuration is not lost. See these instructions on how to customize the config file in the bitnami helm chart.
Apply the following labels to your PostgreSQL pods:
environment: "<environmentname-CHANGEME>"
--For example, prod, dev, qa
component: "database"
db_system: "postgresql"
db_cluster: "<clustername-CHANGEME>"
--For example analytics-dbcluster, webapp-dbcluster- Enter in values for the following parameters (marked
CHANGEMEabove):* `environment` - This is the deployment environment where the PostgreSQL cluster identified by the value of `servers` resides. While this value is optional we highly recommend setting it.
* `db_cluster` - Enter a name to identify this PostgreSQL cluster. This cluster name will be shown in the Sumo Logic dashboards.
* `db_cluster_address` - Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.
* `db_cluster_port` - Enter the database port. If not provided, a default port will be used.notedb_cluster_addressanddb_cluster_portshould reflect exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields).
- Enter in values for the following parameters (marked
For example if your application uses “postgresql-prod.sumologic.com:3306” as the connection string, the field values should be set as follows: db_cluster_address=postgresql-prod.sumologic.com db_cluster_port=3306
If your application connects directly to a given postgresql node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration: host=postgresql-prod.sumologic.com.
Pivoting to Tracing data from Entity Inspector is possible only for “PostgreSQL address” Entities. ::: 2. Do not modify these values, as it will cause the Sumo Logic apps to not function correctly.
* `component: “database”` - This value is used by Sumo Logic apps to identify application components.
* `db_system: “postgresql”` - This value identifies the database system.
Collecting Logs written to Standard output (recommended). The Sumologic-Kubernetes-Collection will automatically capture the logs from stdout and will send the logs to Sumologic. For more information on deploying the Sumo Logic Kubernetes Collection, please see this page.
Collect PostgreSQL logs written to log files (optional). If your PostgreSQL service is writing its logs to log files, you can use a sidecar to send log files to stdout. To do this:
- Determine the location of the PostgreSQL log file on Kubernetes.
- Install the Sumo Logic tailing sidecar operator.
- Add the following annotation in addition to the existing annotations.Example:
annotations:
tailing-sidecar:sidecarconfig;container_name:<mount_volume>:/<path_of_postgresql_log_file_name>annotations:
tailing-sidecar: sidecarconfig;data:/pg_data/postgresql.log - Make sure that the PostgreSQL pods are running and annotations and labels are applied. Verify by using the command:
kubectl describe pod <PostgreSQL_pod_name> - Sumo Logic Kubernetes collection will automatically start collecting logs from the pods having the annotations defined above.
Since pods are frequently killed and spawned it’s recommended to use operators like this postgresql operator so that when new pods are created the annotations and labels are automatically applied using the ConfigMap or CRD based configurations.
Add an FER to normalize the fields in Kubernetes environments. This step is not needed if using application components solution terraform script. Labels created in Kubernetes environments automatically are prefixed with
pod_labels. To normalize these for our app to work, we need to create a Field Extraction Rule if not already created for Database Application Components. To do so:- Go to Manage Data > Logs > Field Extraction Rules.
- Click the + Add button on the top right of the table.
- The Add Field Extraction Rule form will appear:
- Enter the following options:
- Rule Name. Enter the name as App Component Observability - Database.
- Applied At. Choose Ingest Time
- Scope. Select Specific Data
- Scope: Enter the following keyword search expression:
pod_labels_environment=* pod_labels_component=database \
pod_labels_db_system=* pod_labels_db_cluster=* - Parse Expression. Enter the following parse expression:
| if (!isEmpty(pod_labels_environment), pod_labels_environment, "") as environment
| pod_labels_component as component
| pod_labels_db_system as db_system
| if (!isEmpty(pod_labels_db_cluster), pod_labels_db_cluster, null) as db_cluster - Click Save to create the rule.
- Verify logs are flowing into Sumo Logic by running the following logs query
component="database" and db_system="postgresql"
We use the Telegraf Operator for PostgreSQL metric collection and the Sumo Logic Installed Collector for collecting PostgreSQL logs. The diagram below illustrates the components of the PostgreSQL collection in a non-Kubernetes environment for each database server. Telegraf runs on the same system as PostgreSQL, and uses the PostgreSQL Extensible input plugin to obtain PostgreSQL metrics, and the Sumo Logic output plugin to send the metrics to Sumo Logic. PostgreSQL logs are sent to Sumo Logic Local File Source on Installed Collector.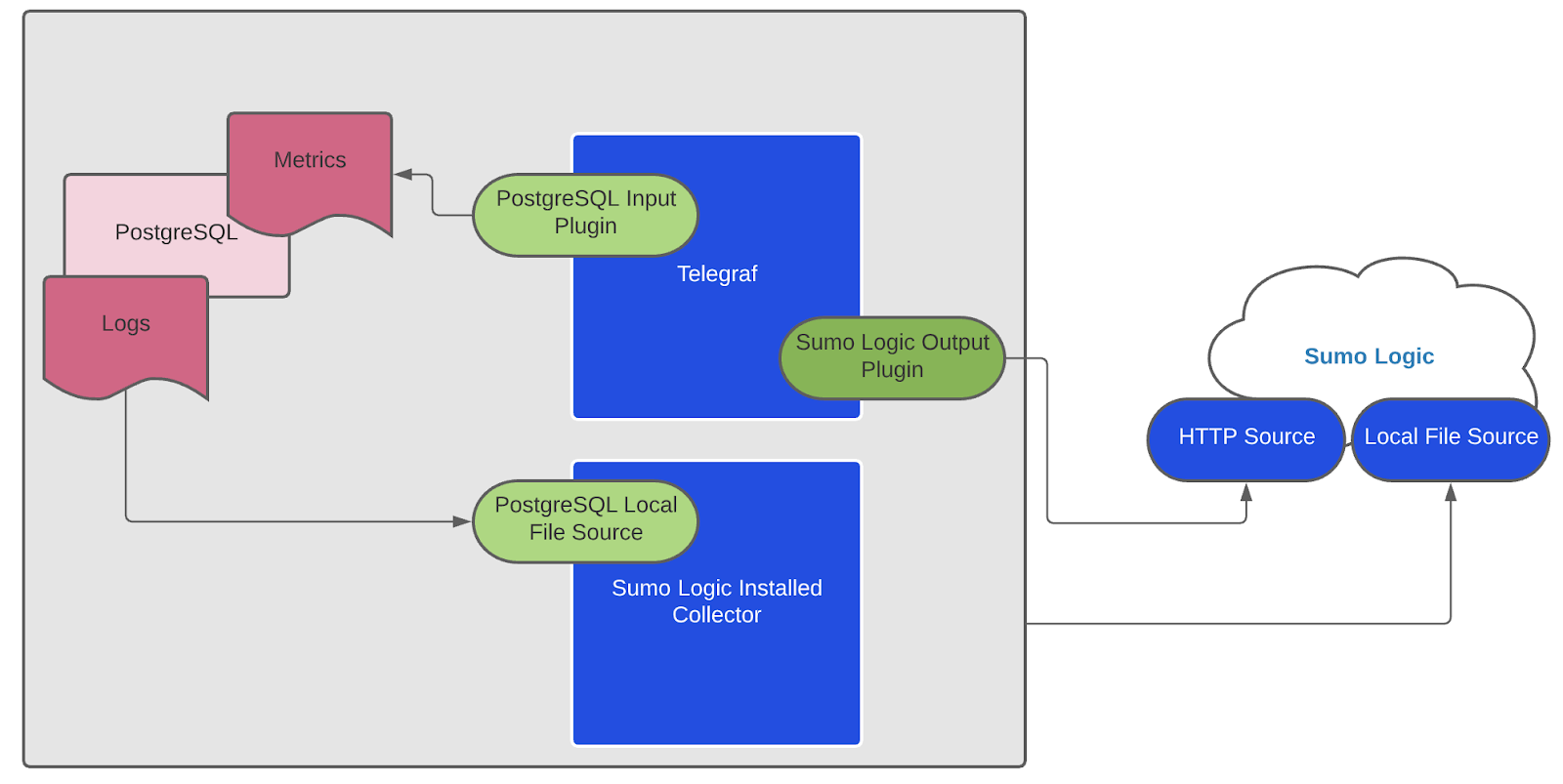
This section provides instructions for configuring metrics collection for the Sumo Logic App for PostgreSQL. Follow the below instructions to set up the metric collection for a given node in a PostgreSQL cluster.
Configure Metrics Collection
- Configure a Hosted Collector. To create a new Sumo Logic hosted collector, perform the steps in the Configure a Hosted Collector section of the Sumo Logic documentation.
- Configure a HTTP Logs and Metrics Source. Create a new HTTP Logs and Metrics Source in the hosted collector created above by following these instructions. . Make a note of the HTTP Source URL.
- Install Telegraf. Use the following steps to install Telegraf on each database server node
- Configure and start Telegraf. As part of collecting metrics data from Telegraf, we will use the Postgresql extensible input plugin to get data from Telegraf and the Sumo Logic output plugin to send data to Sumo Logic.
- Create or modify telegraf.conf in
/etc/telegraf/telegraf.d/and copy and paste the text from this file. - Enter values for the following parameters (marked with
CHANGE_ME) in the downloaded file.
* In the input plugins section, `[[inputs.postgresql_extensible]]`:
* `address` - Specify the db user, db name, and password used for connecting to the database. This is the user you created for monitoring the PosgreSQL database in [Step 1](#step-1-configure-metrics-collection). For example: `host=localhost dbname=postgres user=postgres password=mypassword sslmode=disable`.
* In the tags section, `[inputs.postgresql_extensible.tags]`:
* `environment` - This is the deployment environment where the Postgresql cluster resides. For example dev, prod or qa. While this value is optional we highly recommend setting it.
* `db_cluster` - Enter a name to identify this PostgreSQL cluster. This cluster name will be shown in the Sumo Logic dashboards. For example: analytics-dbcluster, webapp-dbcluster.
* `db_cluster_address` - Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.
* `db_cluster_port` - Enter the database port. If not provided, a default port will be used.notedb_cluster_addressanddb_cluster_portshould reflect the exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields). - Create or modify telegraf.conf in
For example, if your application uses “postgresql-prod.sumologic.com:3306” as the connection string, the field values should be set as follows: db_cluster_address=postgresql-prod.sumologic.com db_cluster_port=3306
If your application connects directly to a given PostgreSQL node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration: host=postgresql-prod.sumologic.com
Pivoting to Tracing data from Entity Inspector is possible only for “PostgreSQL address” Entities. :::
* In the output plugins section, `[[outputs.sumologic]]`:
* `url` - This is the HTTP source URL created in Step 2 (Configure a HTTP Logs and Metrics Source). Please see [this doc](/1021/merge/docs/send-data/collect-from-other-data-sources/collect-metrics-telegraf/configure-telegraf-output-plugin) for more information on additional parameters for configuring the Sumo Logic Telegraf output plugin.
* **Do not modify these values**, as they will cause the Sumo Logic apps to not function correctly.
* `data_format = “prometheus”` In the output plugins section which is `[[outputs.sumologic]]` This indicates that metrics should be sent in the Prometheus format to Sumo Logic
* `component = “database”` - In the input plugins section which is `[[inputs.postgresql_extensible.tags]]` - This value is used by Sumo Logic apps to identify application components.
* `db_system = “postgresql”` - In the input plugins sections which is `[[inputs.postgresql_extensible.tags]]` - This value identifies the database system.
* For other optional parameters like databases, max_lifetime please refer to [this plugin documentation](https://github.com/influxdata/telegraf/blob/master/plugins/inputs/postgresql_extensible/README.md) for configuring the postgresql_extensible input plugin for Telegraf. Here is an example [sample_telegraf.conf](https://sumologic-app-data.s3.amazonaws.com/dashboards/PostgreSQL/sample_postgresql_onprem_telegraf.conf) file.
* See [this doc](https://github.com/influxdata/telegraf/blob/master/docs/CONFIGURATION.md#agent) for more parameters that can be configured in the Telegraf agent globally.
- Once you have finalized your telegraf.conf file, you can start or reload the telegraf service using instructions from the doc. At this point, PostgreSQL metrics should start flowing into Sumo Logic.
Collecting Metrics from Multiple databases (optional)
If you want to monitor multiple databases, copy and paste the text from this file and create another [[inputs.postgresql_extensible]] section. This section contains only those queries which are meant to be run for each database. Click here to see an example.
Configure Logs Collection
Perform the steps outlined below for each PostgreSQL database server.
- Configure logging in PostgreSQL
- Locate your local PostgreSQL postgresql.conf configuration file in the database data_directory. For more information, see the PostgreSQL File Locations documentation. By default it’s located at
/var/lib/pgsql/<version>/data/postgresql.conf. You can runSHOW config_filecommand inside your server’s psql shell to get the location. After determining the location of conf file, modify the PostgreSQL postgresql.conf configuration file logging parameters - Connect to the database server (using SSH) in a terminal window.
- Open postgresql.conf configuration file.
- Under the ERROR REPORTING AND LOGGING section of the file, use following config parameters. For more information on the following parameters, click here.
log_destination = 'stderr'
logging_collector = on
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 1d
log_min_duration_statement = 250
log_connections = on
log_duration = on
log_hostname = on
log_timezone = 'UTC'
log_min_messages = 'WARNING'
log_line_prefix = '%m [%p] %q%u@%d ' - Save the postgresql.conf file and restart the postgresql server:
sudo service postgresql restart
- Locate your local PostgreSQL postgresql.conf configuration file in the database data_directory. For more information, see the PostgreSQL File Locations documentation. By default it’s located at
- Configure an Installed Collector. To add an Installed collector, perform the steps as defined on the page Configure an Installed Collector.
- Configuring a Local File Source. To add a Local File Source source for PostgreSQL do the following:
- Add a Local File Source in the installed collector configured in the previous step.
- Configure the Local File Source fields as follows:
* **Name.** (Required)
* **Description.** (Optional)
* **File Path (Required).** Enter the path to your log file.By default postgreSQL log files are located in `/var/lib/pgsql/<version>/data/log/*.log`
* **Source Host.** Sumo Logic uses the hostname assigned by the OS unless you enter a different hostname
* **Source Category.** Enter any string to tag the output collected from this Source, such as **PostgreSQL/Logs**. (The Source Category metadata field is a fundamental building block to organize and label Sources. For details see[ Best Practices](/docs/send-data/best-practices).)- Fields. Set the following fields:
* `component` = database
* `db_system` = postgresql
* `db_cluster` = <Your_Postgresql_Cluster_Name> (For example analytics-dbcluster, webapp-dbcluster)
* `environment` = <Environment_Name> (For example dev, prod or qa)
* `db_cluster_address` - Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.
* `db_cluster_port` - Enter the database port. If not provided, a default port will be used.notedb_cluster_addressanddb_cluster_portshould reflect exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields).
For example, if your application uses “postgresql-prod.sumologic.com:3306” as the connection string, the field values should be set as follows: db_cluster_address=postgresql-prod.sumologic.com db_cluster_port=3306
If your application connects directly to a given PostgreSQL node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration: host=postgresql-prod.sumologic.com
Pivoting to Tracing data from Entity Inspector is possible only for “PostgreSQL address” Entities. :::
- Ensure that the
db_clusterandenvironmentvalues are the same as they were configured in the Configure and start telegraf section. - Configure the Advanced section:
* **Enable Timestamp Parsing.** Select Extract timestamp information from log file entries.
* **Time Zone.** Use **the timezone from log file **option.
* **Timestamp Format.** The timestamp format is automatically detected.
* **Encoding. **Select** **UTF-8 (Default).
* **Enable Multiline Processing.** Detect messages spanning multiple lines
* Select Infer Boundaries - Detect message boundaries automatically
- Click Save.
Here’s the sample source.json
{
"api.version":"v1",
"source":{
"name":"PostgreSQL_Logs_Source",
"category":"/PostgreSQL/logs",
"automaticDateParsing":true,
"multilineProcessingEnabled":true,
"useAutolineMatching":true,
"forceTimeZone":false,
"filters":[],
"cutoffTimestamp":0,
"encoding":"UTF-8",
"fields":{
"environment":"dev",
"db_cluster":"analytics_cluster",
"component":"database",
"db_system":"postgresql"
},
"pathExpression":"/var/lib/pgsql/12/data/log/*.log",
"blacklist":[],
"sourceType":"LocalFile"
}
}
At this point, PostgreSQL logs should start flowing into Sumo Logic.
Installing PostgreSQL Alerts
This section provides instructions for installing the Sumo App and Alerts for PostgreSQL, as well as the descriptions of each of the app dashboards. These instructions assume you have already set up collection as described in the Collect Logs and Metrics from PostgreSQL App section.
Sumo Logic has provided out-of-the-box alerts available through Sumo Logic monitors to help you monitor your PostgreSQL cluster. These alerts are built based on metrics and logs datasets and include preset thresholds based on industry best practices and recommendations. For details on the individual alerts, please see the alerts section.
- To install these alerts, you need to have the Manage Monitors role capability.
- Alerts can be installed by either importing them a JSON or a Terraform script.
There are limits to how many alerts can be enabled - please see the Alerts FAQ for details.
Method A: Importing a JSON file
- Download the JSON file describing all the monitors.
- The JSON contains the alerts that are based on Sumo Logic searches that do not have any scope filters and therefore will be applicable to all PostgreSQL clusters, the data for which has been collected via the instructions in the previous sections. However, if you would like to restrict these alerts to specific clusters or environments, update the JSON file by replacing the text
db_system=postgresqlwith<Your Custom Filter> db_system=postgresql. Custom filter examples:- For alerts applicable only to a specific cluster, your custom filter would be:
db_cluster=postgresql-prod.01. - For alerts applicable to all clusters that start with postgresql-prod, your custom filter would be:
db_cluster=postgresql-prod*. - For alerts applicable to a specific cluster within a production environment, your custom filter would be
db_cluster=postgresql-1 and environment=prod. This assumes you have set the optional environment tag while configuring collection.
- For alerts applicable only to a specific cluster, your custom filter would be:
- The JSON contains the alerts that are based on Sumo Logic searches that do not have any scope filters and therefore will be applicable to all PostgreSQL clusters, the data for which has been collected via the instructions in the previous sections. However, if you would like to restrict these alerts to specific clusters or environments, update the JSON file by replacing the text
- Go to Manage Data > Alerts > Monitors.
- Click Add:
- Click Import to import monitors from the JSON above.
The monitors are disabled by default. Once you have installed the alerts using this method, navigate to the PostgreSQL folder under Monitors to configure them. See this document to enable monitors, to configure each monitor, to send notification to teams or connections please see the instructions detailed in step 4 of this document.
Method B: Using a Terraform script
- Generate a Sumo Logic access key and ID for a user that has the Manage Monitors role capability in Sumo Logic using these instructions. Please identify which deployment your Sumo Logic account is in, using this link.
- Download and install Terraform 0.13 or later.
- Download the Sumo Logic Terraform package for PostgreSQL alerts: The alerts package is available in the Sumo Logic github repository. You can either download it through the “git clone” command or as a zip file.
- Alert Configuration: After the package has been extracted, navigate to the package directory terraform-sumologic-sumo-logic-monitor/monitor_packages/postgresql/
Edit the postgresql.auto.tfvars file and add the Sumo Logic Access Key, Access Id and Deployment from Step 1 .
access_id = "<SUMOLOGIC ACCESS ID>"
access_key = "<SUMOLOGIC ACCESS KEY>"
environment = "<SUMOLOGIC DEPLOYMENT>"
The Terraform script installs the alerts without any scope filters, if you would like to restrict the alerts to specific clusters or environments, update the variable postgresql_data_source. Custom filter examples:
- A specific cluster
db_cluster=postgresql.prod.01 - All clusters in an environment
environment=prod - For alerts applicable only to a specific cluster, your custom filter would be:
db_cluster=postgresql-.prod.01 - For alerts applicable to all clusters that start with postgresql-prod, your custom filter would be
db_cluster=postgresql-prod* - For alerts applicable to a specific cluster within a production environment, your custom filter would be
db_cluster=postgresql-1 and environment=prod. This assumes you have set the optional environment tag while configuring collection.
All monitors are disabled by default on installation, if you would like to enable all the monitors, set the parameter monitors_disabled to false in this file.
By default, the monitors are configured in a monitor folder called “PostgreSQL”, if you would like to change the name of the folder, update the monitor folder name in this file.
If you would like the alerts to send email or connection notifications, configure these in the file postgresql_notifications.auto.tfvars. For configuration examples, refer to the next section.
- Email and Connection Notification Configuration Examples. To configure notifications, modify the file postgresql_notifications.auto.tfvars file and fill in the connection_notifications and email_notifications sections. See the examples for PagerDuty and email notifications below. See this document for creating payloads with other connection types.
connection_notifications = [
{
connection_type = "PagerDuty",
connection_id = "<CONNECTION_ID>",
payload_override = "{\"service_key\": \"your_pagerduty_api_integration_key\",\"event_type\": \"trigger\",\"description\": \"Alert: Triggered {{TriggerType}} for Monitor {{Name}}\",\"client\": \"Sumo Logic\",\"client_url\": \"{{QueryUrl}}\"}",
run_for_trigger_types = ["Critical", "ResolvedCritical"]
},
{
connection_type = "Webhook",
connection_id = "<CONNECTION_ID>",
payload_override = "",
run_for_trigger_types = ["Critical", "ResolvedCritical"]
}
]
Replace <CONNECTION_ID> with the connection id of the webhook connection. The webhook connection id can be retrieved by calling the Monitors API.
email_notifications = [
{
connection_type = "Email",
recipients = ["abc@example.com"],
subject = "Monitor Alert: {{TriggerType}} on {{Name}}",
time_zone = "PST",
message_body = "Triggered {{TriggerType}} Alert on {{Name}}: {{QueryURL}}",
run_for_trigger_types = ["Critical", "ResolvedCritical"]
}
]
- Install the Alerts
- Navigate to the package directory terraform-sumologic-sumo-logic-monitor/monitor_packages/postgresql/ and run
terraform init. This will initialize Terraform and will download the required components. - Run
terraform planto view the monitors which will be created/modified by Terraform. - Run
terraform apply.
- Navigate to the package directory terraform-sumologic-sumo-logic-monitor/monitor_packages/postgresql/ and run
- Post Installation. If you haven’t enabled alerts and/or configured notifications through the Terraform procedure outlined above, we highly recommend enabling alerts of interest and configuring each enabled alert to send notifications to other people or services. This is detailed in this document.
Installing the PostgreSQL App
Now that you have set up log and metric collection for PostgreSQL, you can install the Sumo Logic App for PostgreSQL to use the pre-configured Searches and dashboards. To install the app, do the following:
Locate and install the app you need from the App Catalog. If you want to see a preview of the dashboards included with the app before installing, click Preview Dashboards.
- From the App Catalog, search for and select the app.
- Select the version of the service you're using and click Add to Library. Version selection is applicable only to a few apps currently. For more information, see the Install the Apps from the Library.
- To install the app, complete the following fields.
- App Name. You can retain the existing name, or enter a name of your choice for the app.
- Data Source. Choose Enter a Custom Data Filter, and enter a custom PostgreSQL cluster filter. Examples:
- For all PostgreSQL clusters
db_cluster=** - For a specific cluster:
db_cluster=postgresql.dev.01. - Clusters within a specific environment:
db_cluster=postgresql-1 and environment=prod. (This assumes you have set the optional environment tag while configuring collection)
- For all PostgreSQL clusters
- Advanced. Select the Location in Library (the default is the Personal folder in the library), or click New Folder to add a new folder.
- Click Add to Library.
Once an app is installed, it will appear in your Personal folder, or other folder that you specified. From here, you can share it with your organization.
Panels will start to fill automatically. It's important to note that each panel slowly fills with data matching the time range query and received since the panel was created. Results won't immediately be available, but with a bit of time, you'll see full graphs and maps.
Viewing PostgreSQL Dashboards
Template variables provide dynamic dashboards that can rescope data on the fly. As you apply variables to troubleshoot through your dashboard, you view dynamic changes to the data for a quicker resolution to the root cause. You can use template variables to drill down and examine the data on a granular level. For more information, see Filter with template variables.
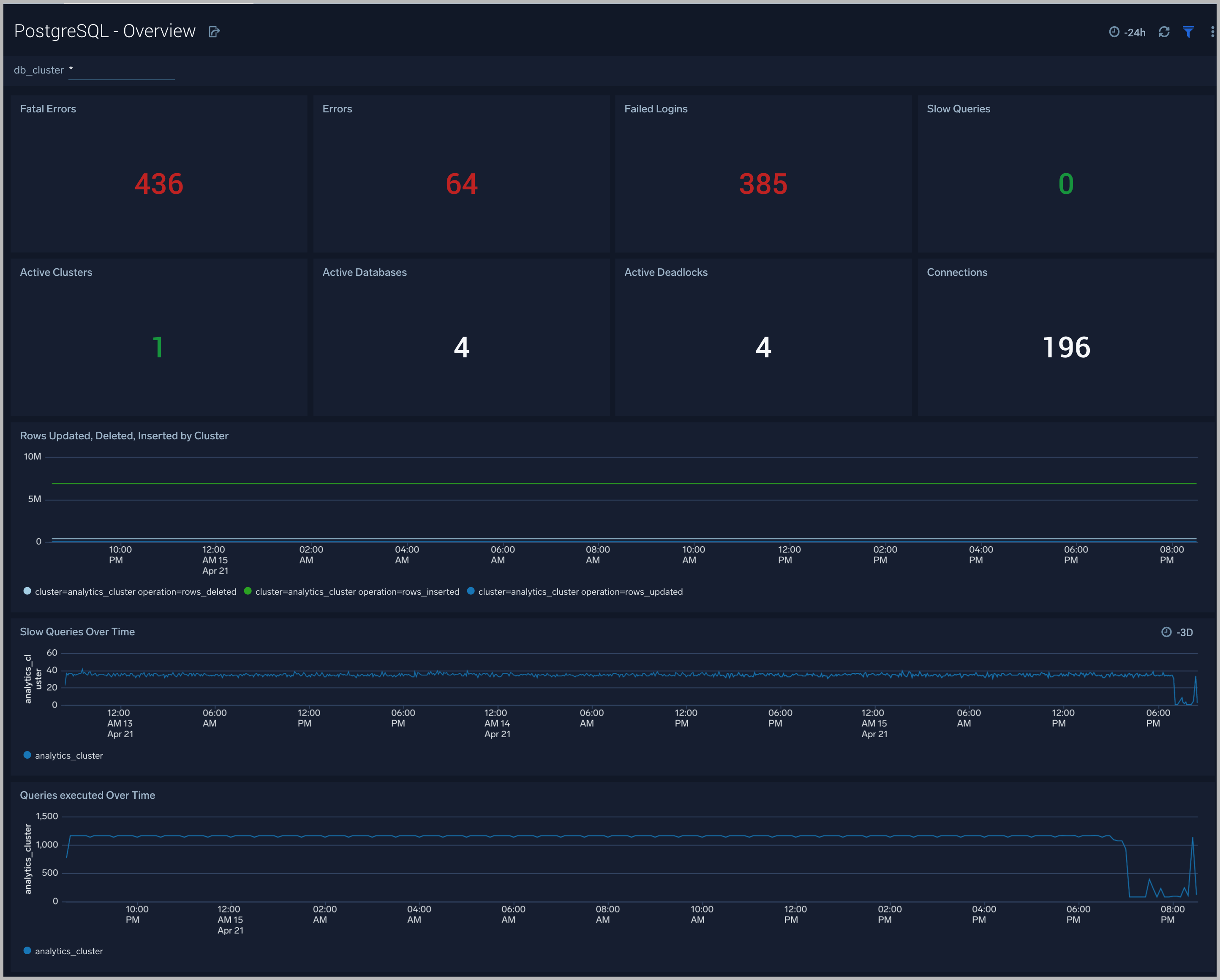
Overview
The PostgreSQL - Overview dashboard gives you an at-a-glance view of the state of your database clusters by monitoring errors, failed logins, slow queries and trends over time.
Use this dashboard to:
- Determine the number of active databases, clusters and deadlocks.
- Drill-down into database errors, failed logins and slow queries.
- Determine if your database or queries need to be tuned based on comparing the number slow queries.
- Monitor the number of insert, update, delete operations by cluster.
Query Execution
The PostgreSQL Query Execution dashboard gives you insights into the number and time taken to execute queries:
Use this dashboard to:
- Monitor query performance and identify slow queries.
- Examine query execution trends.
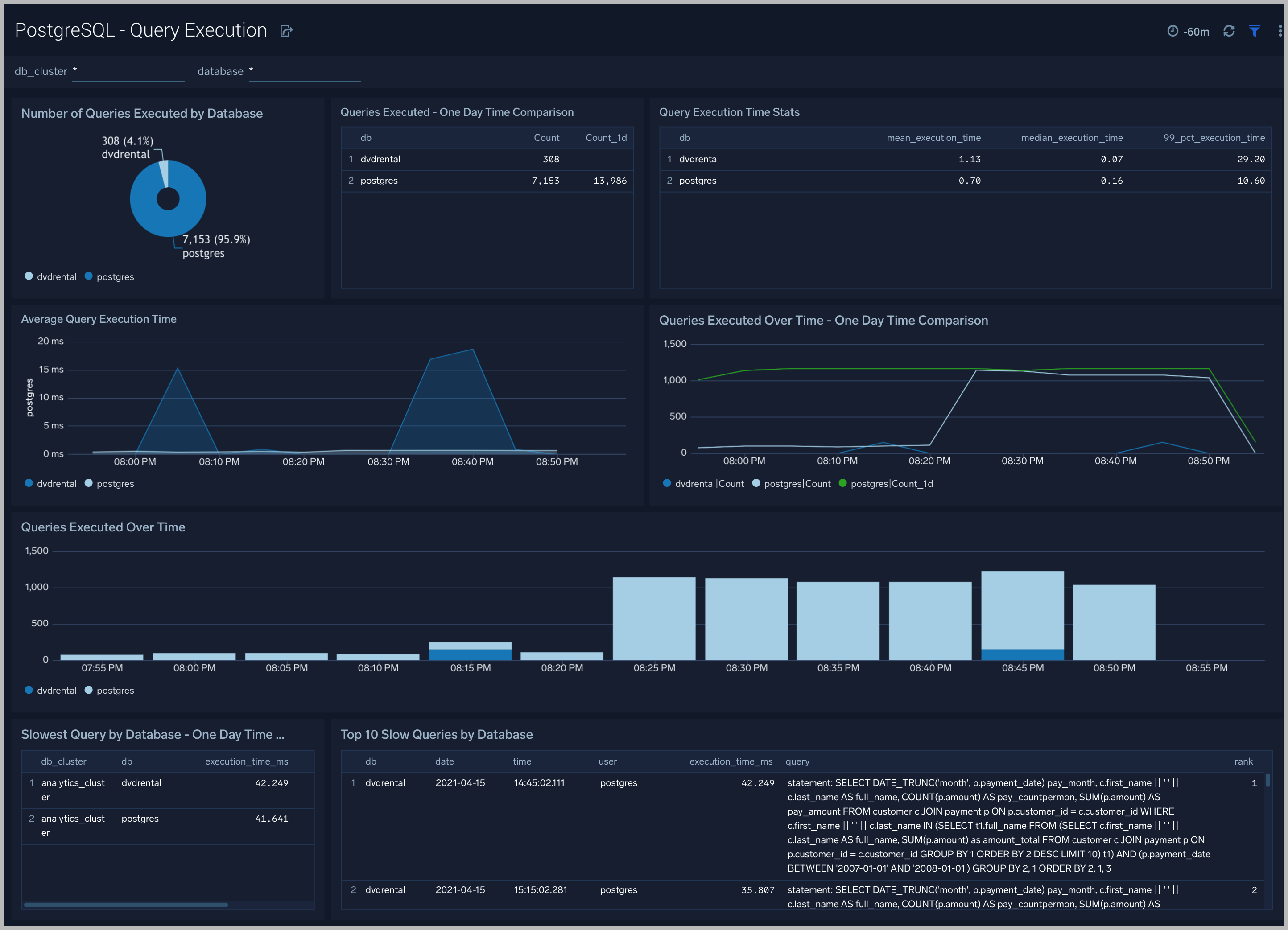
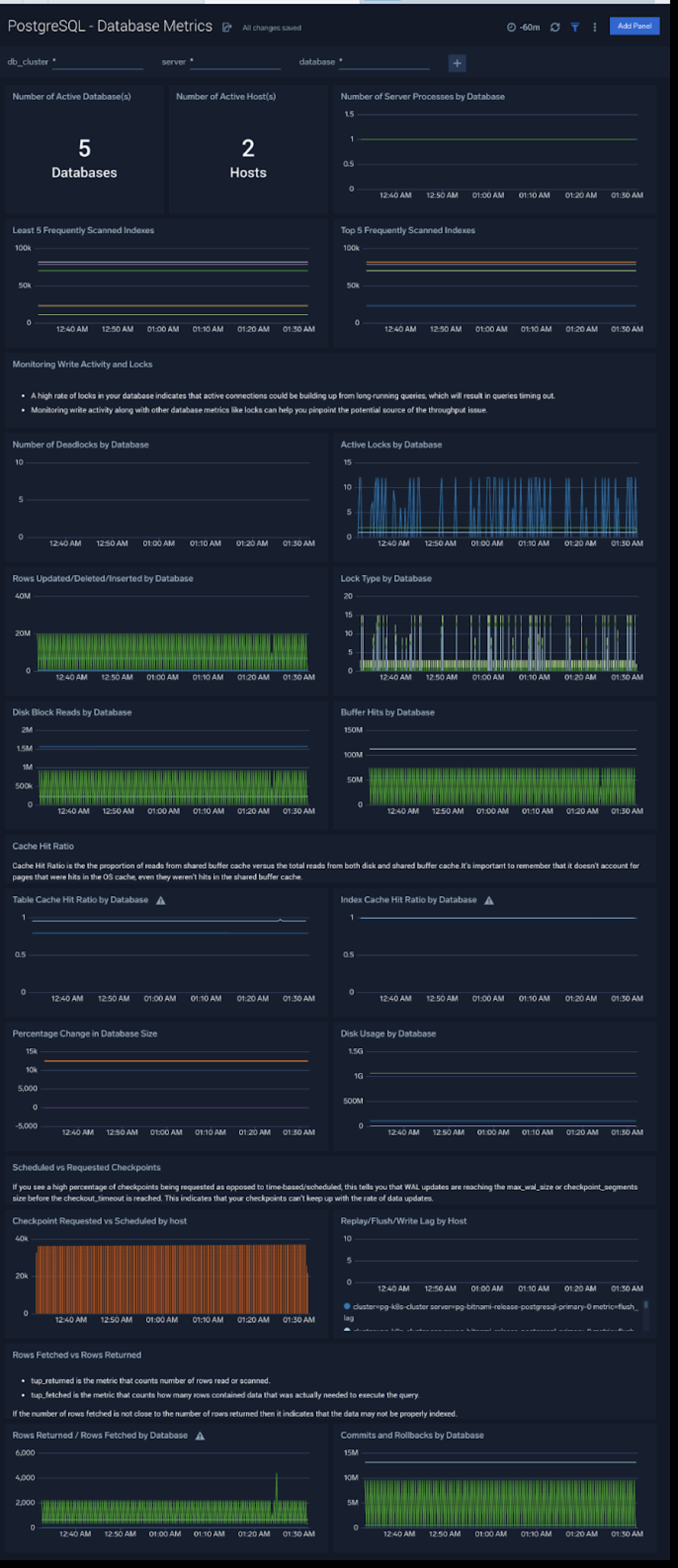
Database Metrics
The PostgreSQL - Database Metrics dashboard allows you to monitor the database performance, which includes disk usage, deadlocks, buffer hits, server processes, commits, rollbacks, and scans.
Use this dashboard to:
- Understand the behavior and performance of your database clusters.
- Monitor database size and disk usage.
- Identify top 5 and least 5 frequently scanned indexes.
Relation and Schema Metrics
The PostgreSQL - Relation and Schema Metrics dashboard allows you to view and analyze the metrics for monitoring the relations and schema in a cluster.
Use this dashboard to:
- Monitor PostgreSQL relation and schema metrics trends over time.
- Monitor sequential scans and index scans and determine if executed queries are accessing them.
- Monitor the size of tables, and query operations which will determine the performance of your queries.
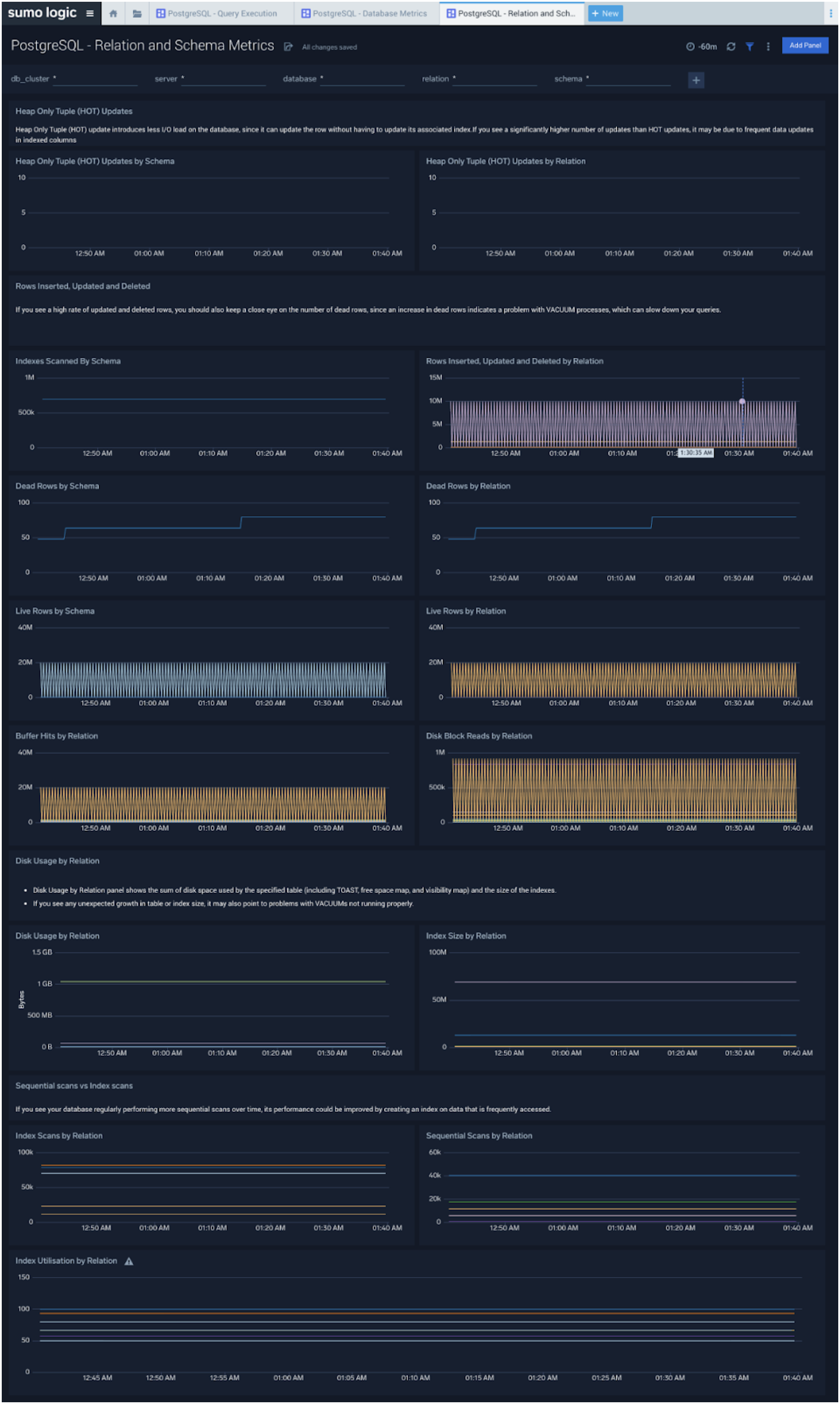
Query performance can degrade with growth in size of table, database and/or indexes. This means that you either need to scale up the database instance, partition your data, or redesign your indexes. Unusual growth in disk space can also mean there are problems with VACUUMs .
If your database regularly performs more sequential scans over time, you can improve its performance by creating an index on frequently accessed data.
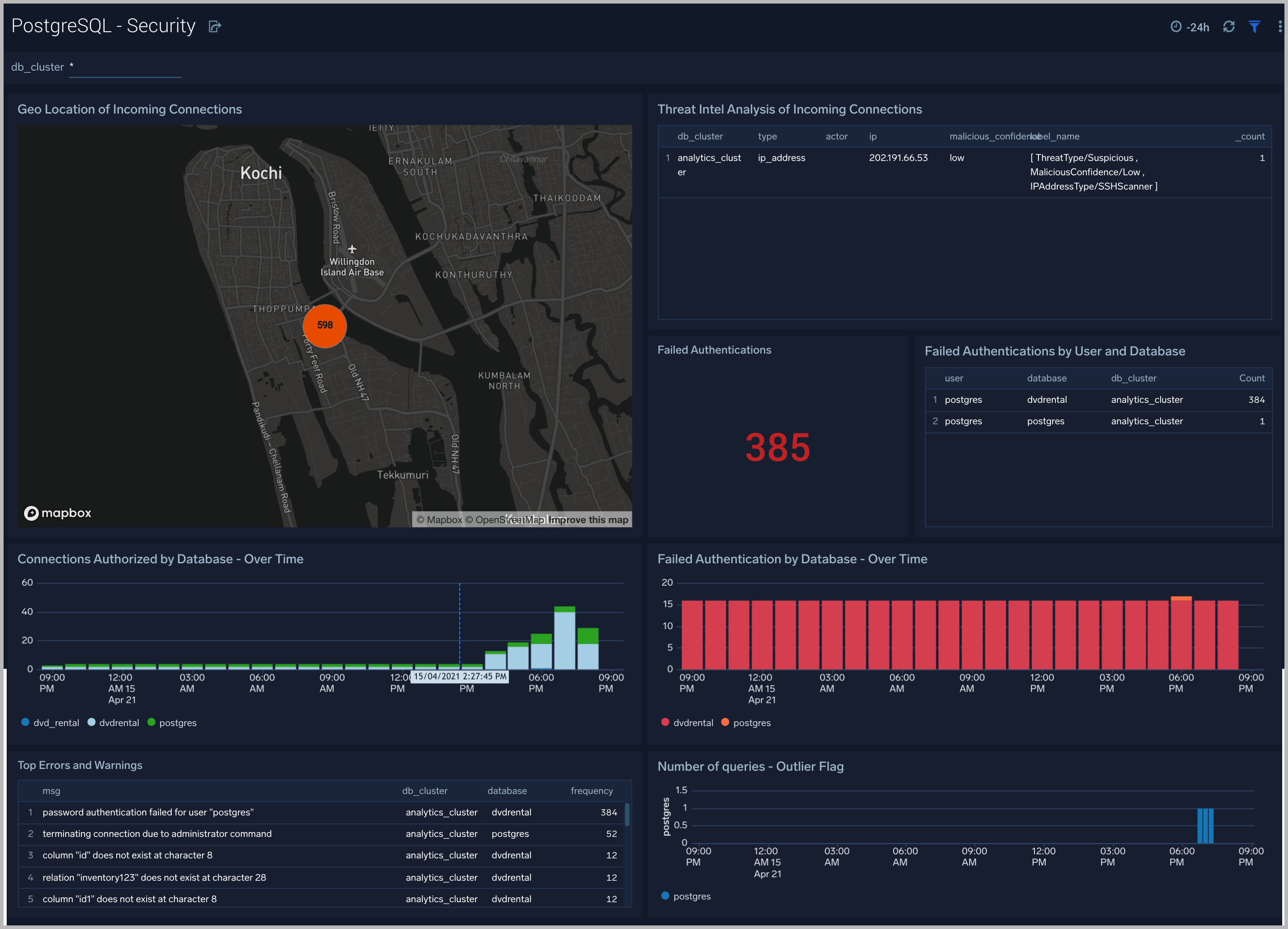
Security
The PostgreSQL - Security dashboard provides insight into locations of incoming connections, failed authentications and top database errors and warnings.
Use this dashboard to:
- Monitor incoming connections, failed authorization requests, and outliers in the number of queries executed outlier.
- Identify known malicious IPs that are accessing your databases and use firewall access control lists to prevent them from sending you traffic going forward.
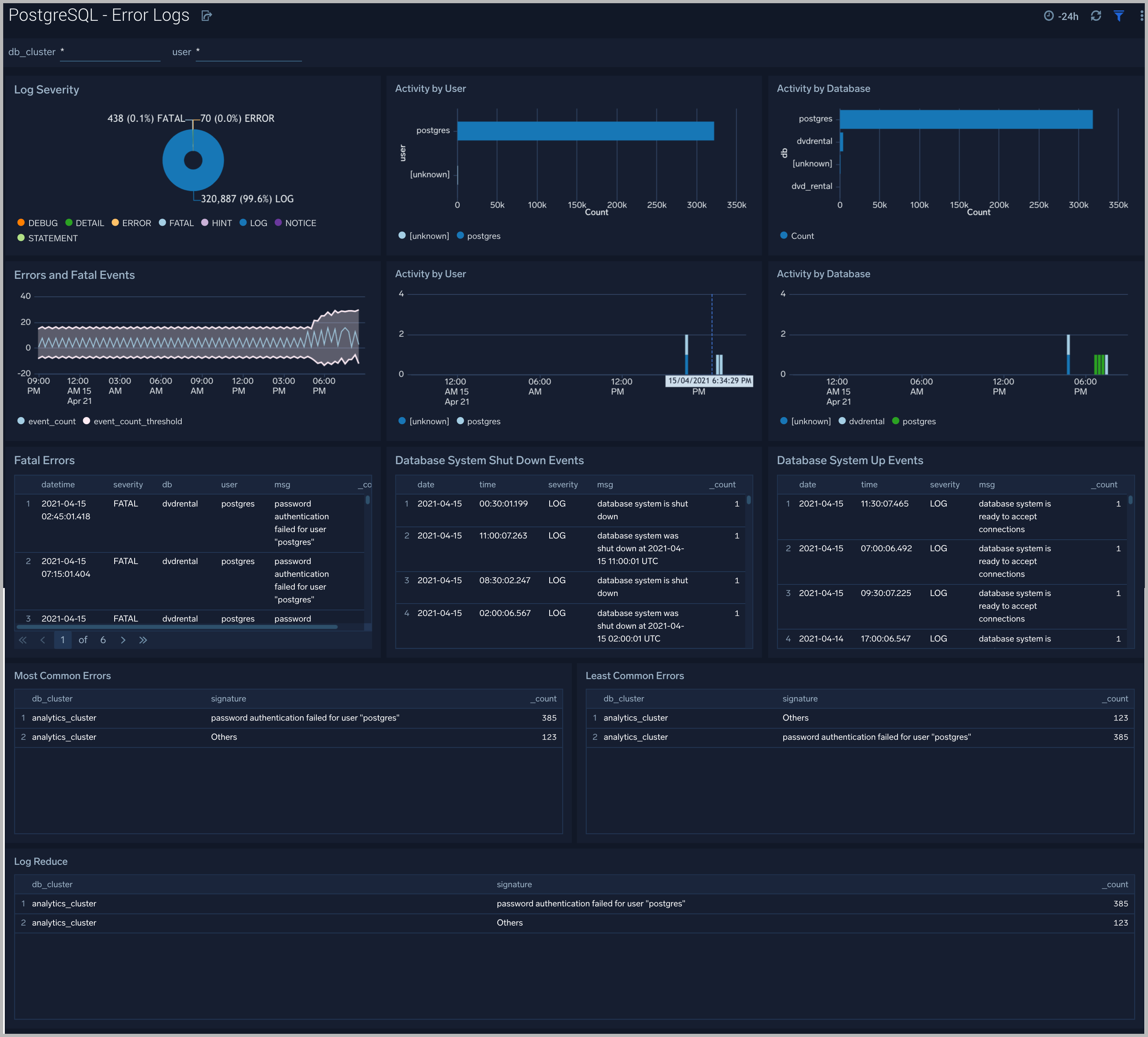
Error Logs
The PostgreSQL - Error Logs dashboard** **provides insight into database error logs by specifically monitoring errors, user activity, database activity and database shutdown/start events.
Use this dashboard to:
- Quickly identify errors and patterns in logs for troubleshooting
- Monitor error trends and quickly identify outliers
- Identify unexpected database or user activity
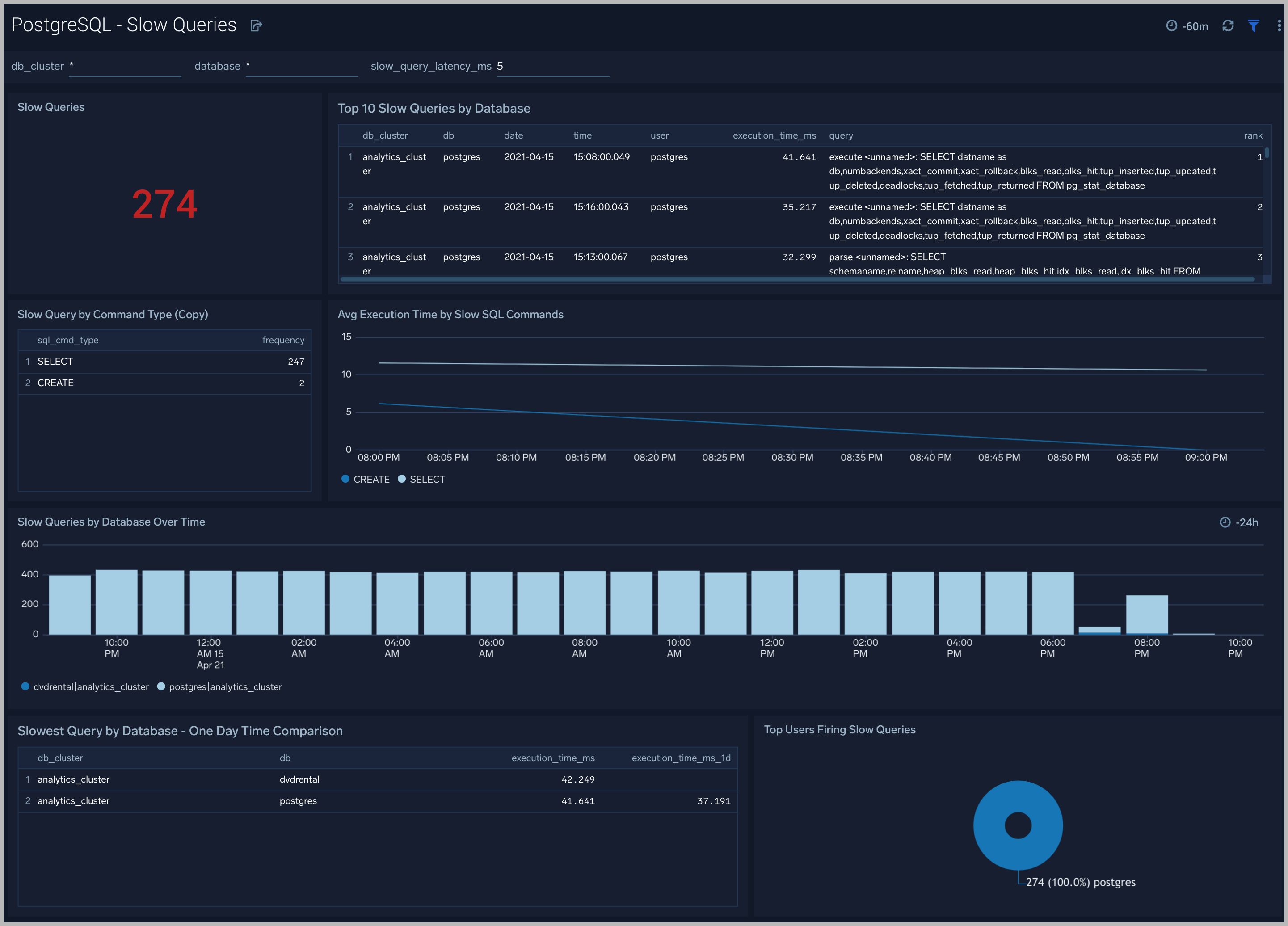
Slow Queries
The PostgreSQL - Slow Queries dashboard** **provides insights into all slow queries executed on the database.
Use this dashboard to:
- Identify all slow queries
- Monitor users and databases running slow queries
- Determine which SQL commands are slower than others
- Examine slow query trends to determine if there are periodic performance bottlenecks in your database clusters
Relation Metrics
The PostgreSQL - Relation Metrics dashboard allows you to view and analyze the metrics for monitoring the relations in a schema.
Use this dashboard to:
- Monitor PostgreSQL relation metrics (disk blocks, buffer hits, hot updates etc) trends over time.
- Monitor sequential scans and index scans and determine if executed queries are accessing them for a relation.
- Track index utilization of existing indexes in a relation
PostgreSQL Metrics
Here are the metrics available for PostgreSQL.
| PostgreSQL Metrics List |
| postgresql_numbackends |
| postgresql_xact_commit |
| postgresql_xact_rollback |
| postgresql_blks_read |
| postgresql_blks_hit |
| postgresql_tup_inserted |
| postgresql_tup_updated |
| postgresql_tup_deleted |
| postgresql_deadlocks |
| postgresql_tup_fetched |
| postgresql_tup_returned |
| postgresql_checkpoints_timed |
| postgresql_checkpoints_req |
| postgresql_buffers_checkpoint |
| postgresql_buffers_clean |
| postgresql_buffers_backend |
| postgresql_stat_ssl_compression_count |
| postgresql_replication_delay |
| postgresql_replication_lag |
| postgresql_replay_lag |
| postgresql_flush_lag |
| postgresql_write_lag |
| postgresql_db_size |
| postgresql_num_locks |
| postgresql_seq_scan |
| postgresql_seq_tup_read |
| postgresql_idx_scan |
| postgresql_idx_tup_fetch |
| postgresql_n_tup_ins |
| postgresql_n_tup_upd |
| postgresql_n_tup_del |
| postgresql_n_tup_hot_upd |
| postgresql_n_live_tup |
| postgresql_n_dead_tup |
| postgresql_idx_scan |
| postgresql_idx_tup_read |
| postgresql_idx_tup_fetch |
| postgresql_idx_blks_read |
| postgresql_idx_blks_hit |
| postgresql_heap_blks_read |
| postgresql_heap_blks_hit |
| postgresql_idx_blks_read |
| postgresql_idx_blks_hit |
| postgresql_index_size |
| postgresql_table_size |
PostgreSQL Alerts
Sumo Logic provides out-of-the-box alerts available via Sumo Logic monitors. These alerts are built based on logs and metrics datasets and have preset thresholds based on industry best practices and recommendations.
Sumo Logic provides the following out-of-the-box alerts for PostgreSQL:
The metrics queries are derived as per Prometheus rules.
| Alert Name | Alert Description and conditions | Alert Condition | Recover Condition |
|---|---|---|---|
| PostgreSQL - Instance Down | This alert fires when the Postgres instance is down | >=1 | < 1 |
| PostgreSQL - TooManyConnections | This alert fires when we detect that a PostgreSQL instance has too many (90% of allowed) connections) | >= 90 | < 90 |
| PostgreSQL - SlowQueries | This alert fires when we detect that the PostgreSQL instance is executing slow queries | >= 1 | < 1 |
| PostgreSQL - Commit Rate Low | This alert fires when we detect that Postgres seems to be processing very few transactions. | commit rate < 10 | commit rate >= 10 |
| PostgreSQL - High Rate of Statement Timeout | This alert fires when we detect Postgres transactions show a high rate of statement timeouts | timeout rate > 3 | timeout rate < 3 |
| PostgreSQL - High Rate Deadlock | This alert fires when we detect deadlocks in a Postgres instance | deadlock rate >=1 | deadlock rate <1 |
| PostgreSQL - High Replication Lag | This alert fires when we detect that the Postgres Replication lag (in bytes) is high. | > 1000000000 bytes | < 1000000000 bytes |
| PostgreSQL - SSL Compression Active | This alert fires when we detect database connections with SSL compression are enabled. This may add significant jitter in replication delay. Replicas should turn off SSL compression via sslcompression=0 in recovery.conf | > 0 | <= 0 |
| PostgreSQL - Too Many Locks Acquired | This alert fires when we detect that there are too many locks acquired on the database. If this alert happens frequently, you may need to increase the postgres setting max_locks_per_transaction. | > 20 percent of max allowed locks assuming default max connection = 100 and max_locks per transaction = 64 | < 20 percent of max allowed locks |
| PostgreSQL - Access from Highly Malicious Sources | This alert will fire when a Postgres instance is accessed from known malicious IP addresses. | > 0 | <= 0 |