Data Tiers FAQs
This page has frequently asked questions about Data Tiers. For information about selecting the data tier for your use case, features of each tier, and the differences among tiers, see Data Tiers.
In which Sumo subscriptions are Data Tiers available?
The Continuous Data Tier is available in all Sumo subscriptions. Frequent and Infrequent are available only if you have Sumo Logic Enterprise Suite.
Is the Infrequent Tier available to existing Cloud Flex customers?
No, Infrequent is only available to customers that have Cloud Flex Credits packaging.
Can I restrict access to Infrequent or Frequent data to select users?
You can use Sumo Logic’s role-based access control (RBAC) to restrict access to partitions in the Infrequent or Frequent tiers. Although you can’t use a role search filter to restrict access to a partition by name, you can filter by the metadata that forms the routing expression for a partition.
For example, if you want to strict access to a partition whose routing expression is:
_sourceCategory=staging/*
You can create a role with this role search filter:
!(_sourceCategory=staging/*)
Then, you assign that role to any user that shouldn’t have access to data in that partition.
If you change the routing expression for partition in the future, you should update the role search filter accordingly.
How does pricing work for Infrequent Tier searches?
When you run a search In the Infrequent Tier, the cost of a search is based on how much data Sumo Logic scans in order to return your search results. At the current rate, your account’s Cloud Flex Credits are consumed at a rate of .016 per 1 GB scanned.
The table below shows how many credits would be consumed for the same query over multiple time ranges.
| Query | Data Scanned | Credits Consumed |
|---|---|---|
| Search 1/2 day of data | 500 | 500 * 0.016 = 8 |
| Search 1 day of data | 1000 | 1000 * 0.016 = 16 |
| Search 2 days of data | 2000 | 2000 * 0.016 = 32 |
How can I get visibility into our Infrequent Tier search costs?
The Account Overview page shows the credits your org has consumed for Infrequent searches.
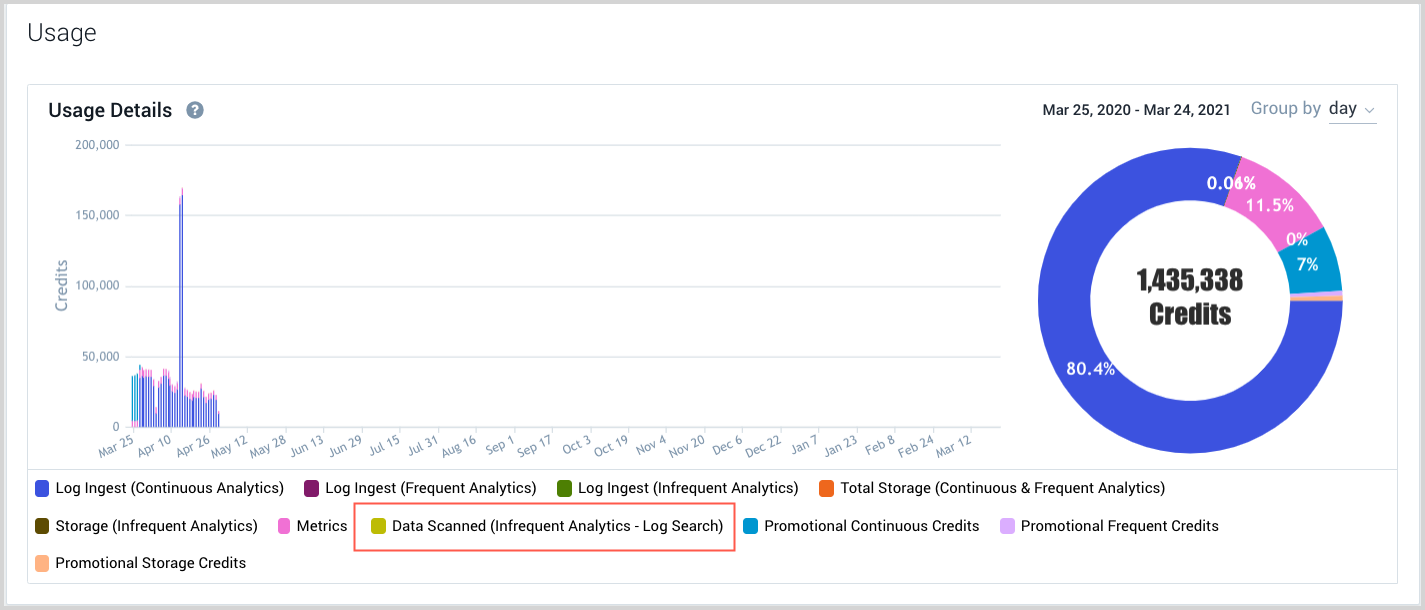
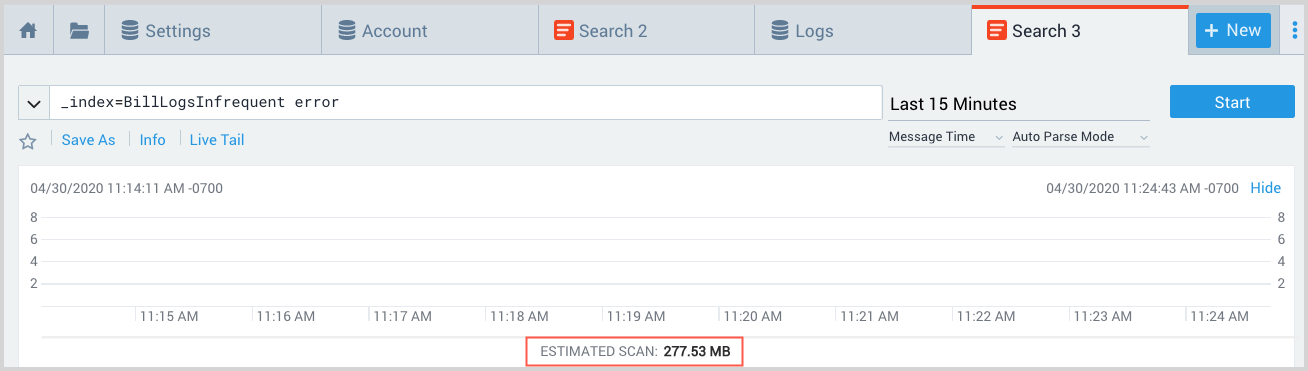
In addition, when you enter an Infrequent query, before you run it, the search page shows an estimate of the amount of data that will be scanned for that query.
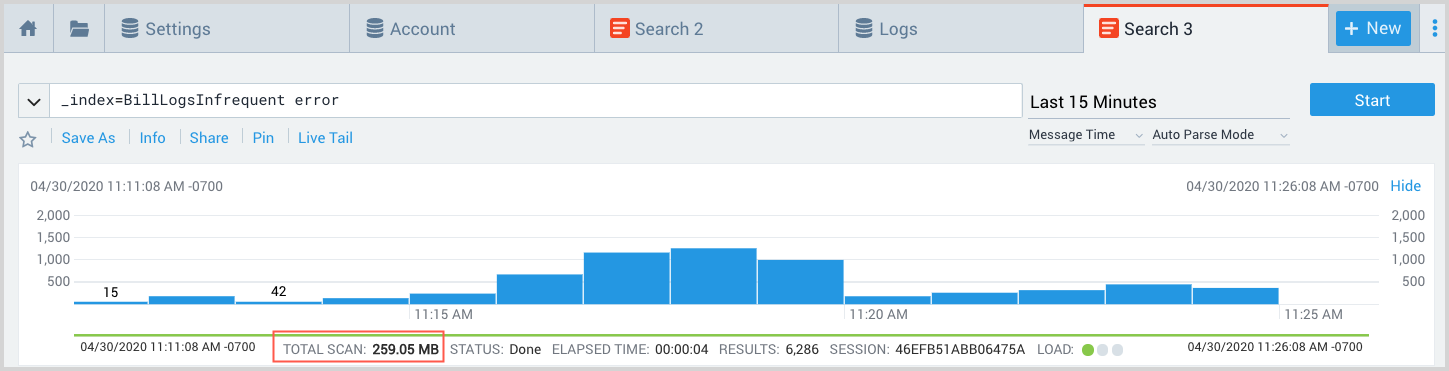
After you run an Infrequent query, you can see the volume of data that was actually scanned.
How do I create partitions to reroute data to a different tier later?
These recommendations apply if you don’t use Data Streams, currently in beta. You can change the scope of a Data Stream to change the target tier.
Add a custom metadata field at either the collector or source level, and then use it as the routing expression for the partition. For example, you could create a field named usage, and set it to "infrequent".
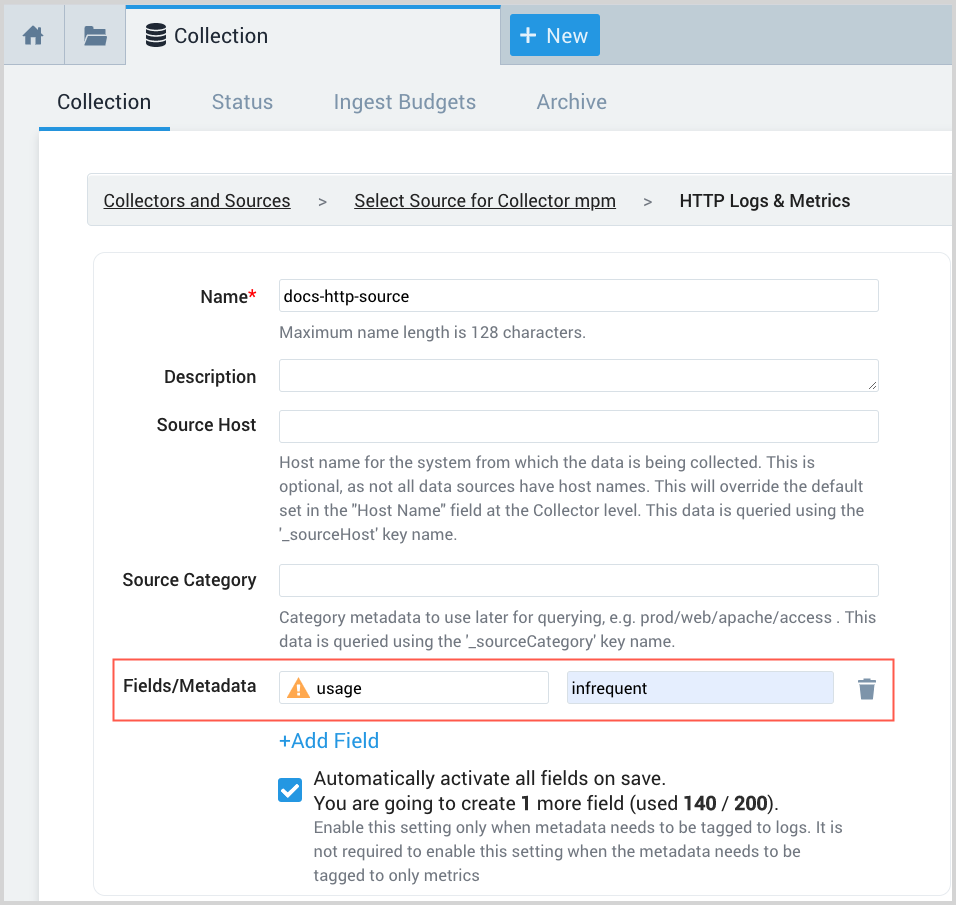
Then, when you create a new partition, you can use the field in the scoping expression along with other scoping rules.
In the future, if you want to change the data that goes into the partition, you can just update the usage field.
What are the best practices for creating partitions to minimize infrequent search costs?
One of the main ways to control costs is to split your data into multiple partitions.
Assume you have three different services sending logs to Sumo. There a couple of approaches you can take:
- Create one partition per service. All the logs for that service go there. This approach can be leveraged if each team owns a service, and they typically query the logs within their service to find issues.
- Create one partition per log type (Debug, Infra, and so on). This approach can be leveraged if most of the time, the team searches one log type per query. For example, team only queries Debugs logs, and typically queries other logs like Database, OS logs in separate queries.
How can I control the cost of queries in the Infrequent Data tier?
The cost of queries depends on two factors:
- Partition size — The partition size governs the volume of data that will be scanned by a search against it.
- Time range of the query — The time range further reduces the volume of data scanned.
Using keywords or other metadata in a query will not reduce the amount of data scanned. For example, the inclusion of a keyword and custom field in the scope of the query below does not reduce the amount of data that Sumo Logic will scan. Sumo Logic will scan all data in the partition named “ybase_partition”
_index=ybase_partition (error and cluster=nxt)
The table below should give you a sense of how the number of partitions you use and the query time range affects the volume of data scanned.
| Query Time Range | Number of Partitions Queried | Data Scanned |
|---|---|---|
| 1 day | 1 | 2 TB |
| 1/2 day | 1 | 1 TB |
| 4 day | 1 | 8 TB |
| 1 day | 2 | 4 TB |
| 1/2 day | 2 | 2 TB |
| 2 days | 2 | 8 TB |
There are two ways you can control the cost of running queries data in the Infrequent tier:
- Logically apportion your data, depending on how you plan to query it, into multiple partitions, instead of creating a single large partition. Try to limit queries to a single partition as much as possible.
- Try to use a restrictive time range, instead of running a query with very long time range.
What is an ideal size for a partition for Infrequent Tier?
We recommend you configure partitions to have less than 5 TB per day flowing into them. This practice:
- Reduces the cost of each query.
- Results in faster queries, since less data has to be scanned.
How will searching my data be affected by storing data in different tiers?
See the Searching Data Tiers topic.
Will I be able to use Scheduled Searches on the lower data tiers?
You can use Scheduled Searches on the Infrequent tier.