Sumo Logic App for Cassandra

The Cassandra app is a unified logs and metrics app that helps you monitor the availability, performance, health, and resource utilization of your Cassandra clusters. Preconfigured dashboards provide insight into cluster health, resource utilization, cache/Gossip/Memtable statistics, compaction, garbage collection, thread pools, and write paths.
Log Types
The app supports Logs and Metrics from the open-source version of Cassandra. The App is tested on the 3.11.10 version of Cassandra.
Cassandra has three main logs, system.log, debug.log, and gc.log which hold general logging messages, debugging logging messages, and java garbage collection logs respectively.
These logs by default live in ${CASSANDRA_HOME}/logs, but most Linux distributions relocate logs to /var/log/cassandra. Operators can tune this location as well as what levels are logged using the provided logback.xml file. For more details on Cassandra logs, see this link.
The Sumo Logic App for Cassandra supports metrics generated by the Jolokia2 plugin for Telegraf. The app assumes prometheus format Metrics.
Collecting Logs and Metrics for Cassandra
This section provides instructions for configuring log and metric collection for the Sumo Logic App for Cassandra.
Step 1: Configure Fields in Sumo Logic
Create the following Fields in Sumo Logic prior to configuring collection. This ensures that your logs and metrics are tagged with relevant metadata, which is required by the app dashboards. For information on setting up fields, see Sumo Logic Fields.
- Kubernetes environments
- Non-Kubernetes environments
If you're using Cassandra in a Kubernetes environment, create the fields:
pod_labels_componentpod_labels_environmentpod_labels_db_systempod_labels_db_clusterpod_labels_db_cluster_addresspod_labels_db_cluster_port
If you're using Cassandra in a non-Kubernetes environment, create the fields:
componentenvironmentdb_systemdb_clusterpoddb_cluster_addressdb_cluster_port
Step 2: Configure Collection for Cassandra
- Kubernetes environments
- Non-Kubernetes environments
In Kubernetes environments, we use the Telegraf Operator, which is packaged with our Kubernetes collection. You can learn more about it here.
The diagram below illustrates how data is collected from Cassandra in a Kubernetes environment. In the architecture shown below, make up the metric collection pipeline: Telegraf, Prometheus, Fluentd and FluentBit.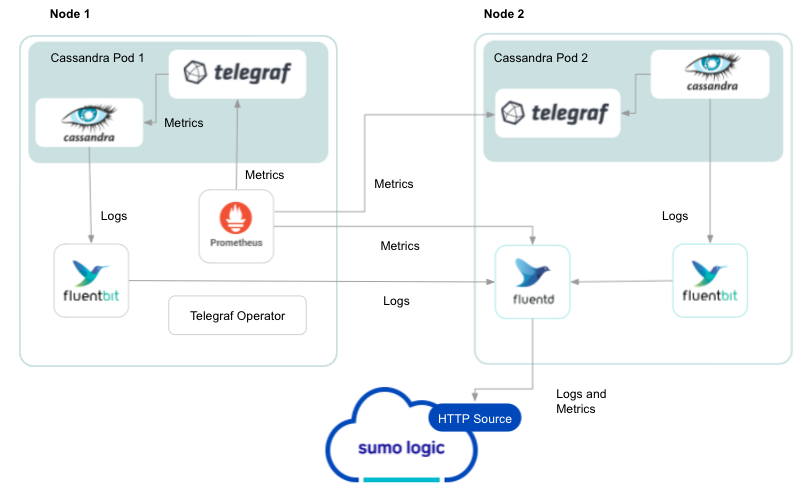
The first service in the pipeline is Telegraf. Telegraf collects metrics from Cassandra. Note that we’re running Telegraf in each pod we want to collect metrics from as a sidecar deployment for example, Telegraf runs in the same pod as the containers it monitors. Telegraf uses the Jolokia2 input plugin to obtain metrics. For simplicity, the diagram doesn’t show the input plugins.
The injection of the Telegraf sidecar container is done by the Telegraf Operator. We also have Fluentbit that collects logs written to standard out and forwards them to FluentD, which in turn sends all the logs and metrics data to a Sumo Logic HTTP Source.
It’s assumed that you're using the latest helm chart version. If not, upgrade using the instructions here.
Configure Metrics Collection
Follow the steps listed below to collect Cassandra metrics from a Kubernetes environment.
- Set up your Kubernetes Collection with the Telegraf Operator.
- On your Cassandra Pods, add the following annotations:
annotations:
telegraf.influxdata.com/class: sumologic-prometheus
prometheus.io/scrape: "true"
prometheus.io/port: "9273"
telegraf.influxdata.com/inputs: |+
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "cassandra_java_"
[inputs.jolokia2_agent.tags]
environment="prod"
component="database"
db_system="cassandra"
db_cluster="cassandra_on_premise"
dc = "IDC1"
[[inputs.jolokia2_agent.metric]]
name = "Memory"
mbean = "java.lang:type=Memory"
[[inputs.jolokia2_agent.metric]]
name = "GarbageCollector"
mbean = "java.lang:name=*,type=GarbageCollector"
tag_keys = ["name"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name=”OperatingSystem”
mbean=”java.lang:type=OperatingSystem”
paths = [“FreePhysicalMemorySize", "AvailableProcessors", "SystemCpuLoad", "TotalPhysicalMemorySize", "TotalSwapSpaceSize", "SystemLoadAverage"]
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "cassandra_"
[inputs.jolokia2_agent.tags]
environment="ENV_TO_BE_CHANGED"
component="database"
db_system="cassandra"
db_cluster="cassandra_on_premise"
db_cluster_address = “ENV_TO_BE_CHANGED”
db_cluster_port = “ENV_TO_BE_CHANGED”
dc = "IDC1"
[[inputs.jolokia2_agent.metric]]
name = "TableMetrics"
mbean = "org.apache.cassandra.metrics:name=*,scope=*,keyspace=*,type=Table"
tag_keys = ["name", "scope","keyspace"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "DroppedMessageMetrics"
mbean = "org.apache.cassandra.metrics:name=*,scope=*,type=DroppedMessage"
tag_keys = ["name", "scope"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "ClientMetrics"
mbean = "org.apache.cassandra.metrics:type=Client,name=*"
tag_keys = ["name"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "ThreadPoolMetrics"
mbean = "org.apache.cassandra.metrics:type=ThreadPools,path=*,scope=*,name=*"
tag_keys = ["name", "scope", "path"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "CacheMetrics"
mbean = "org.apache.cassandra.metrics:type=Cache,scope=*,name=*"
tag_keys = ["name", "scope"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "CommitLogMetrics"
mbean = "org.apache.cassandra.metrics:type=CommitLog,name=*"
tag_keys = ["name"] field_prefix = "$1_"
Enter in values for the following parameters (marked ENV_TO_BE_CHANGED above):
telegraf.influxdata.com/inputs- This contains the required configuration for the Telegraf Cassandra Input plugin. Please refer to this doc for more information on configuring the Cassandra input plugin for Telegraf. As Telegraf will be run as a sidecar, the host should always be localhost.- In the input plugins section (
[[inputs.jolokia2_agent]]):urls- The URL to the Cassandra server. This can be a comma-separated list to connect to multiple Cassandra servers. Please see this doc for more information on additional parameters for configuring the Cassandra input plugin for Telegraf.
- In the tags section (
[[inputs.jolokia2_agent]]):environment- This is the deployment environment where the Cassandra cluster identified by the value of servers resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.db_cluster- Enter a name to identify this Cassandra cluster. This cluster name will be shown in the Sumo Logic dashboards.db_cluster_address- Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.db_cluster_port- Enter the database port. If not provided, a default port will be used
- In the input plugins section (
Here’s an explanation for additional values set by this configuration that we request you do not modify, as they will cause the Sumo Logic apps to not function correctly.
telegraf.influxdata.com/class: sumologic-prometheus- This instructs the Telegraf operator what output to use. This should not be changed.prometheus.io/scrap: "true"- This ensures our Prometheus will scrape the metrics.prometheus.io/port: "9273"- This tells prometheus what ports to scrape on. This should not be changed.telegraf.influxdata.com/inputs- In the tags section (
[inputs.jolokia2_agent.tags]):component: “database”- This value is used by Sumo Logic apps to identify application components.db_system: “cassandra”- This value identifies the database system.
- In the tags section (
db_cluster_address and db_cluster_port should reflect exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields).
For example if your application uses “cassandra-prod.sumologic.com:3306” as the connection string, the field values should be set as follows: db_cluster_address=cassandra-prod.sumologic.com
db_cluster_port=3306.
If your application connects directly to a given Cassandra node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration:
host=cassandra-prod.sumologic.com.
Pivoting to Tracing data from Entity Inspector is possible only for “Cassandra address” Entities.
See this doc for more parameters that can be configured in the Telegraf agent globally. 3. Sumo Logic Kubernetes collection will automatically start collecting metrics from the pods having the labels and annotations defined in the previous step. 4. Verify metrics in Sumo Logic.
Configure Logs Collection
This section explains the steps to collect Cassandra logs from a Kubernetes environment.
Add labels on your Cassandra pods to capture logs from standard output on Kubernetes.
- Apply following labels to the Cassandra pods:Please enter values for the following parameters:
environment: "<Ex prod, stag>"
component: "database"
db_system: "cassandra"
db_cluster: "<Your_Cassandra_Cluster_Name>"--Enter Default if you do not have one.
db_cluster_address: <your cluster’s hostname or ip address or service endpoint>
db_cluster_port: <database port>
environment- This is the deployment environment where the Cassandra cluster identified by the value of servers resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.db_cluster- Enter a name to identify the Cassandra cluster. The cluster name will be shown in the Sumo Logic dashboards.Do not modify the following values as it will cause the Sumo Logic apps to not function correctly.
component: “database”- This value is used by Sumo Logic apps to identify application components.db_system: “Cassandra”- This value identifies the database system.db_cluster_address- Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.db_cluster_port- Enter the database port. If not provided, a default port will be used
- Apply following labels to the Cassandra pods:
db_cluster_address and db_cluster_port should reflect exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields).
For example if your application uses “cassandra-prod.sumologic.com:3306” as the connection string, the field values should be set as follows:
db_cluster_address=cassandra-prod.sumologic.com
db_cluster_port=3306
If your application connects directly to a given Cassandra node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration:
host=cassandra-prod.sumologic.com
Pivoting to Tracing data from Entity Inspector is possible only for “Cassandra address” Entities.
For all other parameters, see this doc for more parameters that can be configured in the Telegraf agent globally.
(Optional) Collecting Cassandra Logs from a Log File on Kubernetes.
- Determine the location of the Cassandra log file on Kubernetes. This can be determined from the Cassandra logback.xml for your Cassandra cluster along with the mounts on the Cassandra pods.
- Install the Sumo Logic tailing sidecar operator.
- Add the following annotation in addition to the existing annotations.Example:
annotations:
tailing-sidecar: sidecarconfig;<mount>:<path_of_Cassandra_log_file>/ <Cassandra_log_file_name>annotations:
tailing-sidecar: sidecarconfig;data:/opt/bitnami/cassandra/logs/cassandra.log - Make sure that the Cassandra pods are running and annotations are applied by using the command:
kubectl describe pod <Cassandra_pod_name> - Sumo Logic Kubernetes collection will automatically start collecting logs from the pods having the annotations defined above.
- Verify logs in Sumo Logic.
Add an FER to normalize the fields in Kubernetes environments. Labels created in Kubernetes environments automatically are prefixed with pod_labels. To normalize these for our app to work, we need to create a Field Extraction Rule if not already created for Proxy Application Components. This step is not needed if one is using application components solution terraform script. To do so:
- Go to Manage Data > Logs > Field Extraction Rules.
- Click the + Add button on the top right of the table.
- The Add Field Extraction Rule form will appear:
Enter the following options:
- Rule Name. Enter the name as App Observability - Database.
- Applied At. Choose Ingest Time
- Scope. Select Specific Data
- Scope: Enter the following keyword search expression:
pod_labels_environment=* pod_labels_component=database pod_labels_db_system=* pod_labels_db_cluster=* - Parse Expression. Enter the following parse expression:
if (!isEmpty(pod_labels_environment), pod_labels_environment, "") as environment
| pod_labels_component as component
| pod_labels_db_system as db_system
| if (!isEmpty(pod_labels_db_cluster), pod_labels_db_cluster, null) as db_clusterClick Save to create the rule.
Cassandra metrics collection setup can be done in two ways.
- Using Telegraf and Installed Collector
- Using Open Telemetry Collection
Both the methods require the Jolokia agent to collect metrics. The steps to configure Jolokia JVM Agent in Cassandra are as below:
- Download the latest Jolokia JVM agent jar file (example:
jolokia-jvm-1.3.3-agent.jar) from here. - Copy the downloaded jar file to Cassandra’s lib folder (example:
/usr/share/cassandra/lib). - In
cassandra-env.shfile, enable/add the following lines:# Jolokia javaagent
JVM_OPTS="$JVM_OPTS -javaagent:$CASSANDRA_HOME/lib/jolokia-jvm-1.3.3-agent.jar" - Restart Cassandra service.
Below we have defined both the ways in which collection can be configured.
Method A: Using Telegraf and Installed Collector
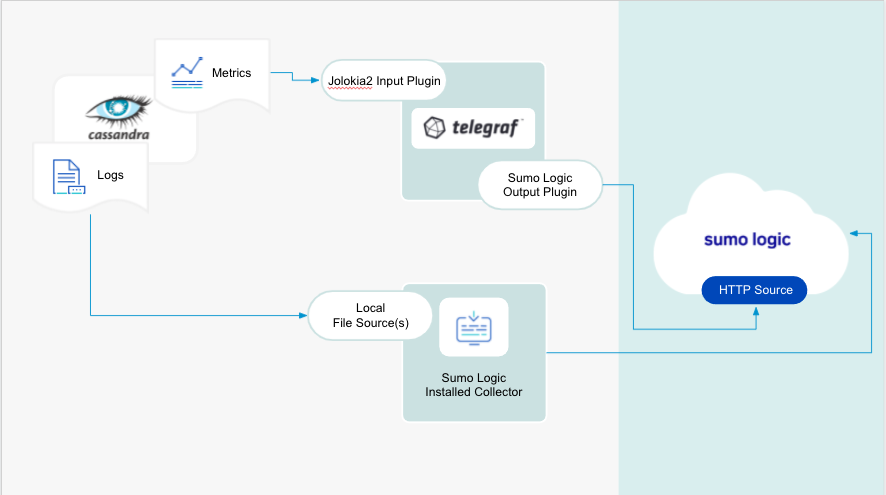
We use the Telegraf operator for Cassandra metric collection and Sumo Logic Installed Collector for collecting Cassandra logs. The diagram below illustrates the components of the Cassandra collection in a non-Kubernetes environment. Telegraf runs on the same system as Cassandra, and uses the Jolokia2 input plugin to obtain Cassandra metrics, and the Sumo Logic output plugin to send the metrics to Sumo Logic. Logs from Cassandra on the other hand are sent to a Sumo Logic Local File source.
Configure Metrics Collection
This section provides instructions for configuring metrics collection for the Sumo Logic App for Cassandra.
Configure a Hosted Collector. To create a new Sumo Logic hosted collector, perform the steps in the Configure a Hosted Collector section of the Sumo Logic documentation.
Configure an HTTP Logs and Metrics Source. Create a new HTTP Logs and Metrics Source in the hosted collector created above by following these instructions. Make a note of the HTTP Source URL.
Install Telegraf. Use the following steps to install Telegraf.
Configure and start Telegraf. As part of collecting metrics data from Telegraf, we will use the jolokia2 input plugin to get data from Telegraf and the Sumo Logic output plugin to send data to Sumo Logic.
Create or modify telegraf.conf and copy and paste the text below:
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "cassandra_java_"
[inputs.jolokia2_agent.tags]
environment="<Your_Environment_Name>"
component="database"
db_system="cassandra"
db_cluster="<Your_Cassandra_Cluster_Name>"
dc = "IDC1"
[[inputs.jolokia2_agent.metric]]
name = "Memory"
mbean = "java.lang:type=Memory"
[[inputs.jolokia2_agent.metric]]
name = "GarbageCollector"
mbean = "java.lang:name=*,type=GarbageCollector"
tag_keys = ["name"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name="OperatingSystem"
mbean="java.lang:type=OperatingSystem"
paths=["FreePhysicalMemorySize","AvailableProcessors","SystemCpuLoad","TotalPhysicalMemorySize","TotalSwapSpaceSize","SystemLoadAverage"]
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "cassandra_"
[inputs.jolokia2_agent.tags]
environment="<Your_Environment_Name>"
component="database"
db_system="cassandra"
db_cluster="<Your_Cassandra_Cluster_Name>"
db_cluster_address = "ENV_TO_BE_CHANGED"
db_cluster_port = "ENV_TO_BE_CHANGED"
dc = "IDC1"
[[inputs.jolokia2_agent.metric]]
name = "TableMetrics"
mbean = "org.apache.cassandra.metrics:name=*,scope=*,keyspace=*,type=Table"
tag_keys = ["name", "scope","keyspace"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "DroppedMessageMetrics"
mbean = "org.apache.cassandra.metrics:name=*,scope=*,type=DroppedMessage"
tag_keys = ["name", "scope"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "ClientMetrics"
mbean = "org.apache.cassandra.metrics:type=Client,name=*"
tag_keys = ["name"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "ThreadPoolMetrics"
mbean = "org.apache.cassandra.metrics:type=ThreadPools,path=*,scope=*,name=*"
tag_keys = ["name", "scope", "path"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "CacheMetrics"
mbean = "org.apache.cassandra.metrics:type=Cache,scope=*,name=*"
tag_keys = ["name", "scope"]
field_prefix = "$1_"
[[inputs.jolokia2_agent.metric]]
name = "CommitLogMetrics"
mbean = "org.apache.cassandra.metrics:type=CommitLog,name=*"
tag_keys = ["name"]
field_prefix = "$1_"
[[outputs.sumologic]]
url = "<URL Created in Step 3>"
data_format = "prometheus"
[outputs.sumologic.tagpass]
db_cluster=["<Your_Cassandra_Cluster_Name>"]
Please enter values for the following parameters:
- In the input plugins section, which is
[[inputs. jolokia2_agent]]:urls- The URL to the jolokia server. Please see this doc for more information on additional parameters for configuring the Cassandra input plugin for Telegraf.
- In the tags section, which is
[inputs.Cassandra.tags]:environment- This is the deployment environment where the Cassandra cluster identified by the value ofserversresides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.db_cluster- Enter a name to identify this Cassandra cluster. This cluster name will be shown in the Sumo Logic dashboards.db_cluster_address- Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.db_cluster_port- Enter the database port. If not provided, a default port will be used.
Here’s an explanation for additional values set by this configuration that we request you do not modify, as they will cause the Sumo Logic apps to not function correctly.
- In the tags section (
[inputs.jolokia2_agent.tags]):component: “database”- This value is used by Sumo Logic apps to identify application components.db_system: “cassandra”- This value identifies the database system.
db_cluster_address and db_cluster_port should reflect exact configuration of DB client configuration in your application, especially if you instrument it with OT tracing. The values of these fields should match exactly the connection string used by the database client (reported as values for net.peer.name and net.peer.port metadata fields).
For example if your application uses “cassandra-prod.sumologic.com:3306” as the connection string, the field values should be set as follows:
db_cluster_address=cassandra-prod.sumologic.com
db_cluster_port=3306
If your application connects directly to a given Cassandra node, rather than the whole cluster, use the application connection string to override the value of the “host” field in the Telegraf configuration:
host=cassandra-prod.sumologic.com
Pivoting to Tracing data from Entity Inspector is possible only for “Cassandra address” Entities.
- In the output plugins section, which is
[[outputs.sumologic]]:url- This is the HTTP source URL created in step 3. Please see this doc for more information on additional parameters for configuring the Sumo Logic Telegraf output plugin.
- Do not modify the following values as it will cause the Sumo Logic apps to not function correctly.
data_format - “prometheus”In the output plugins section, which is[[outputs.sumologic]]. Metrics are sent in the Prometheus format to Sumo Logicdb_system: “cassandra”- In the input plugins section: This value identifies the database system.component: “database”- In the input plugins section: This value identifies application components.
- For all other parameters please see this doc for more properties that can be configured in the Telegraf agent globally.
Once you have finalized your telegraf.conf file, you can start or reload the telegraf service using instructions from the doc. At this point, Cassandra metrics should start flowing into Sumo Logic.
Configure Logs Collection
This section provides instructions for configuring log collection for Cassandra running on a non-Kubernetes environment.
By default, Cassandra logs are stored in a log file. Sumo Logic supports collecting logs from a local log file by using a local file source via Installed collectors. The installed collector will require you to allow outbound traffic to Sumo Logic endpoints for collection to work. For detailed requirements for Installed collectors, see this page.
Based on your infrastructure and networking setup choose one of these methods to collect Cassandra logs and follow the instructions below to set up log collection:
Configure logging in Cassandra. Cassandra supports logging via the local text log files. Cassandra logs have the following levels of verbosity. To select a level, set loglevel to one of:
- ALL
- TRACE
- DEBUG
- INFO (Default)
- WARN
- ERROR
- OFF
To permanently add debug logging to a class permanently using the logback framework, use nodetool setlogginglevel to check you have the right class before you set it in the logback.xml file in install_location/conf. Modify to include the following line or similar at the end of the file:
<logger name="org.apache.cassandra.gms.FailureDetector" level="DEBUG"/>Restart the node to invoke the change.
Configure Cassandra to log to a Local file. Cassandra provides logging functionality using Simple Logging Facade for Java (SLF4J) with a logback backend. Cassandra has three main logs, the
system.log,debug.log, andgc.logwhich hold general logging messages, debugging logging messages, and java garbage collection logs, respectively.These logs, by default, live in
${CASSANDRA_HOME}/logs, but most Linux distributions relocate logs to/var/log/cassandra. Operators can tune this location as well as what levels are logged using the provided logback.xml file.You can configure logging programmatically or manually. Manual ways to configure logging are:
- Run the nodetool setlogginglevel command.
- Configure the
logback-test.xmlorlogback.xmlfile installed with Cassandra. - Use the JConsole tool to configure logging through JMX.
Logs from the Cassandra log file can be collected via a Sumo Logic Installed collector and a Local File Source as explained in the next section.
Configure a Collector To add an Installed collector, perform the steps as defined on the page Configure an Installed Collector.
Configure a Local File Source. To collect logs directly from your Cassandra machine, use an Installed Collector and a Local File Source.
- Add a Local File Source.
- Configure the Local File Source fields as follows:
- Name. (Required)
- Description. (Optional)
- File Path (Required). Enter the path to your log files. The files are typically located in
/var/log/cassandra/system.log. If you are using a customized path, check thelogback.xmlfile for this information. - Source Host. Sumo Logic uses the hostname assigned by the OS unless you enter a different host name
- Source Category. Enter any string to tag the output collected from this Source, such as Cassandra/Logs. The Source Category metadata field is a fundamental building block to organize and label Sources. For details see Best Practices.
- Fields. Set the following fields:
component = databasedb_system = cassandradb_cluster = <Your_Cassandra_Cluster_Name>environment = <Environment_Name>, such as Dev, QA or Prod.db_cluster_address- Enter the cluster hostname or ip address that is used by the application to connect to the database. It could also be the load balancer or proxy endpoint.db_cluster_port- Enter the database port. If not provided, a default port will be used.
- Configure the Advanced section:
- Enable Timestamp Parsing. Select Extract timestamp information from log file entries.
- Time Zone. Choose the option, Ignore time zone from log file and instead use, and then select your Cassandra Server’s time zone.
- Timestamp Format. The timestamp format is automatically detected.
- Encoding. Select UTF-8 (Default).
- Enable Multiline Processing. Detect messages spanning multiple lines
- Infer Boundaries - Detect message boundaries automatically
- Click Save.
At this point, Cassandra logs should start flowing into Sumo Logic.
Method B: Using Open Telemetry
We use the Telegraf receiver of Sumo Logic OpenTelemetry Distro Collector for Cassandra metric collection and the Sumo Logic Installed Collector for collecting Cassandra logs. Sumo Logic OT distro runs on the same system as Cassandra, and uses the Cassandra Jolokia input plugin for Telegraf to obtain Cassandra metrics, and the Sumo Logic exporter to send the metrics to Sumo Logic. Cassandra Logs are sent to Sumo Logic Local File Source on Installed Collector.
Configure Metrics and Logs Collection
- Install sumologic-otel-collector by following the instructions mentioned here.
- Configure and start sumologic-otel-collector. As part of collecting metrics data from Cassandra, we will use the jolokia2 input plugin for Telegraf to get data from otel and then send data to Sumo Logic. Create or modify config.yaml. Sample config is here. Please enter values for the following parameters.
- Enter Sumo Logic collection details in the section; extensions > sumologic by referring to these instructions. Configure details like collector name, category, install token, endpoint etc.
- In the input plugins section, that is
[[inputs.jolokia2_agent]]:urls- The URL to the jolokia server. Please see this doc for more information on additional parameters for configuring the Cassandra input plugin for Telegraf.
- In the tags section, which is
[inputs.Cassandra.tags]and filelog sectionenvironment- This is the deployment environment where the Cassandra cluster identified by the value of servers resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.db_cluster- Enter a name to identify this Cassandra cluster. This cluster name will be shown in the Sumo Logic dashboards.
- In the exporter plugins section :
- Enter details like
source_categoryandsource_host. Please see this doc for more information on additional parameters for configuring the Sumo Logic Telegraf output plugin.
- Enter details like
- Do not modify the following values as it will cause the Sumo Logic apps to not function correctly.
data_format - “prometheus”In the output plugins section, which is[[outputs.sumologic]]Metrics are sent in the Prometheus format to Sumo Logicdb_system: “cassandra”- In the input plugins section: This value identifies the database system.component: “database”- In the input plugins section: This value identifies application components.
- For all other parameters, see this doc for more properties that can be configured in the Telegraf agent globally.
- Run the Sumo Logic OT Distro using the below command
otelcol-sumo --config config.yaml
At this point, Cassandra metrics and logs should start flowing into Sumo Logic.
Installing Cassandra Monitors
To install these monitors, you must have the Manage Monitors role capability. You can install monitors by importing a JSON file or using a Terraform script.
Sumo Logic has provided pre-packaged alerts available through Sumo Logic monitors to help you proactively determine if a Cassandra cluster is available and performing as expected. These monitors are based on metric and log data and include pre-set thresholds that reflect industry best practices and recommendations. For more information about individual alerts, see Cassandra Alerts.
There are limits to how many alerts can be enabled. For more information, see Monitors for details.
Method A: Importing a JSON file
Download the JSON file that describes the monitors.
The JSON contains the alerts that are based on Sumo Logic searches that do not have any scope filters and therefore will be applicable to all Cassandra clusters, the data for which has been collected via the instructions in the previous sections.
However, if you would like to restrict these alerts to specific clusters or environments, update the JSON file by replacing the text
db_cluster=*with<Your Custom Filter>. Custom filter examples:- For alerts applicable only to a specific cluster, your custom filter would be:
db_cluster=dev-cassandra-01. - For alerts applicable to all clusters that start with
cassandra-prod, your custom filter would be:db_cluster=cassandra-prod*. - For alerts applicable to specific clusters, within a production environment, your custom filter would be:
db_cluster=dev-cassandra-01ANDenvironment=prod. This assumes you have set the optional environment tag while configuring collection.
- For alerts applicable only to a specific cluster, your custom filter would be:
Go to Manage Data > Alerts > Monitors.
Click Add.
Click Import.
On the Import Content popup, enter Cassandra in the Name field, paste the JSON into the popup, and click Import.
The monitors are created in a "Cassandra" folder. The monitors are disabled by default. See the Monitors topic for information about enabling monitors and configuring notifications or connections.
Method B: Using a Terraform script
- Generate an access key and access ID for a user that has the Manage Monitors role capability. For instructions, see Access Keys.
- Download Terraform 0.13 or later and install it.
- Download the Sumo Logic Terraform package for Cassandra monitors. The alerts package is available in the Sumo Logic github repository. You can either download it using the git clone command or as a zip file.
- Alert Configuration. After extracting the package, navigate to the
terraform-sumologic-sumo-logic-monitor/monitor_packages/Cassandra/directory. - Edit the Cassandra.auto.tfvars file and add the Sumo Logic Access Key and Access ID from Step 1 and your Sumo Logic deployment. If you're not sure of your deployment, see Sumo Logic Endpoints and Firewall Security.
access_id = "<SUMOLOGIC ACCESS ID>"
access_key = "<SUMOLOGIC ACCESS KEY>"
environment = "<SUMOLOGIC DEPLOYMENT>"
- The Terraform script installs the alerts without any scope filters, if you would like to restrict the alerts to specific clusters or environments, update the
cassandra_data_sourcevariable. For example:- To configure alerts for a specific cluster, set
cassandra_data_sourceto something likedb_cluster=cassandra.prod.01 - To configure alerts for all clusters in an environment, set
cassandra_data_sourceto something likeenvironment=prod - To configure alerts for multiple clusters using a wildcard, set
cassandra_data_sourceto something likedb_cluster=cassandra-prod* - To configure alerts for...A specific clusters within a specific environment, set
cassandra_data_sourceto something likedb_cluster=cassandra-1andenvironment=prod. This assumes you have configured and applied Fields as described Configure Fields in Sumo Logic step.
- To configure alerts for a specific cluster, set
All monitors are disabled by default on installation. To enable all of the monitors, set the monitors_disabled parameter to false. By default, the monitors will be located in a "Cassandra" folder on the Monitors page. To change the name of the folder, update the monitor folder name in the folder variable in the Cassandra.auto.tfvars file.
If you want your alerts to send email or connection notifications, edit the
Cassandra_notifications.auto.tfvarsfile to populate theconnection_notificationsandemail_notificationssections. Examples are provided below.In the variable definition below, replace
<CONNECTION_ID>with the connection ID of the Webhook connection. You can obtain the Webhook connection ID by calling the Monitors API.
connection_notifications = [
{
connection_type = "PagerDuty",
connection_id = "<CONNECTION_ID>",
payload_override = "{\"service_key\": \"your_pagerduty_api_integration_key\",\"event_type\": \"trigger\",\"description\": \"Alert: Triggered {{TriggerType}} for Monitor {{Name}}\",\"client\": \"Sumo Logic\",\"client_url\": \"{{QueryUrl}}\"}",
run_for_trigger_types = ["Critical", "ResolvedCritical"]
},
{
connection_type = "Webhook",
connection_id = "<CONNECTION_ID>",
payload_override = "",
run_for_trigger_types = ["Critical", "ResolvedCritical"]
}
]
For information about overriding the payload for different connection types, see Set Up Webhook Connections.
email_notifications = [
{
connection_type = "Email",
recipients = ["abc@example.com"],
subject = "Monitor Alert: {{TriggerType}} on {{Name}}",
time_zone = "PST",
message_body = "Triggered {{TriggerType}} Alert on {{Name}}: {{QueryURL}}",
run_for_trigger_types = ["Critical", "ResolvedCritical"]
}
]
- To install the Monitors, navigate to the
terraform-sumologic-sumo-logic-monitor/monitor_packages/Cassandra/directory and runterraform init. This will initialize Terraform and download the required components. - Run
terraform planto view the monitors that Terraform will create or modify. - Run
terraform apply.
Installing the Cassandra App
This section demonstrates how to install the Cassandra App.
Locate and install the app you need from the App Catalog. If you want to see a preview of the dashboards included with the app before installing, click Preview Dashboards.
- From the App Catalog, search for and select the app.
- Select the version of the service you're using and click Add to Library. Version selection applies only to a few apps currently. For more information, see the Install the Apps from the Library.
- To install the app, complete the following fields.
- App Name. You can retain the existing name, or enter a name of your choice for the app.
- Data Source. Choose Enter a Custom Data Filter, and enter a custom SQL Server cluster filter. Examples:
- For all Cassandra clusters:
db_cluster=* - For a specific cluster:
db_cluster=cassandra.dev.01 - Clusters within a specific environment:
db_cluster=cassandra.dev.01andenvironment=prod. This assumes you have set the optional environment tag while configuring collection.
- Advanced. Select the Location in the Library (the default is the Personal folder in the library), or click New Folder to add a new folder.
- Click Add to Library.
Once an app is installed, it will appear in your Personal folder, or another folder that you specified. From here, you can share it with your organization.
Panels will start to fill automatically. It's important to note that each panel slowly fills with data matching the time range query and received since the panel was created. Results won't immediately be available, but with a bit of time, you'll see full graphs and maps.
Viewing Cassandra Dashboards
Overview
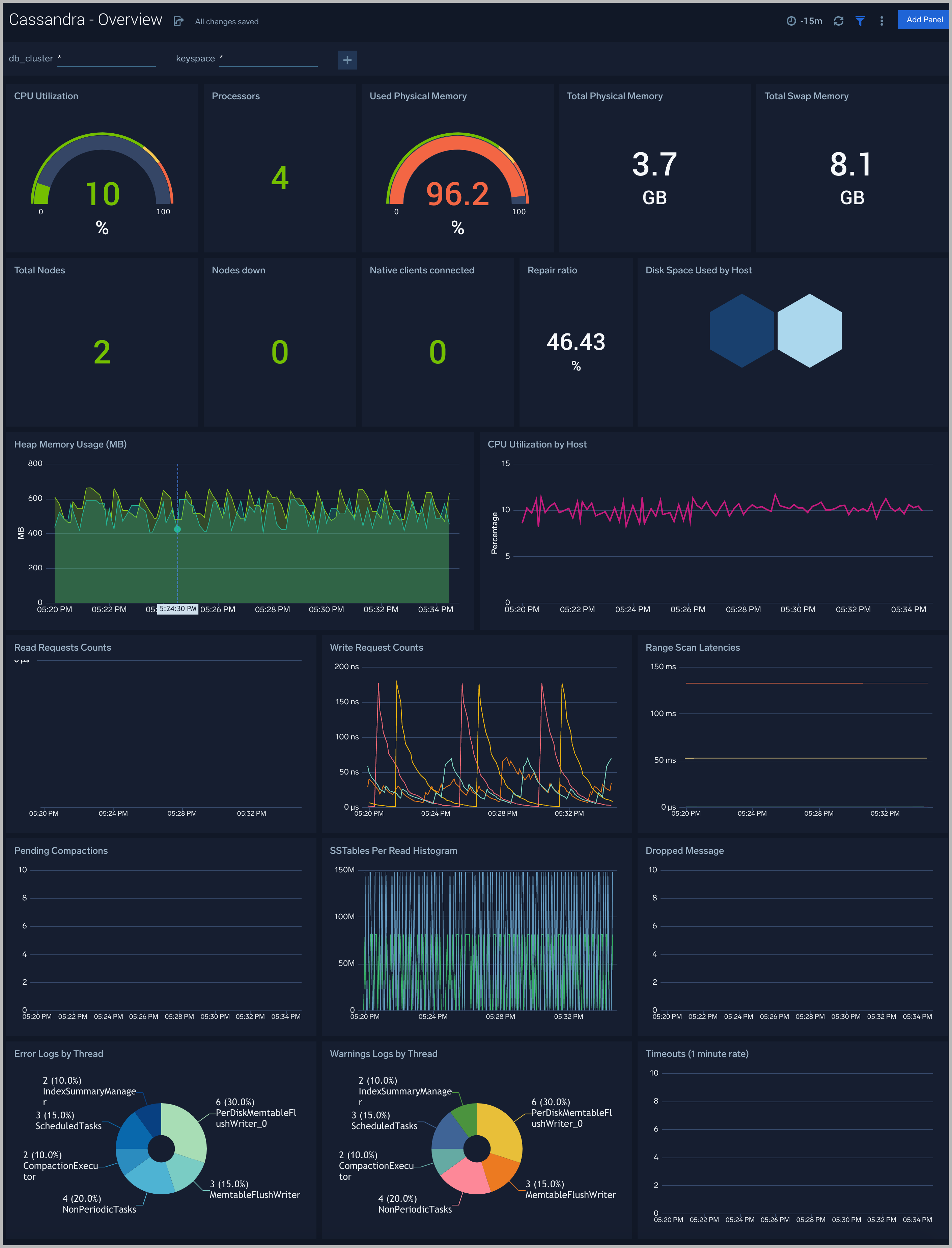
The Cassandra - Overview dashboard provides an at-a-glance view of Cassandra backend and frontend HTTP error codes percentage, visitor location, URLs, and clients causing errors.
Use this dashboard to:
- Identify Frontend and Backend Sessions percentage usage to understand active sessions. This can help you increase the session limit.
- Gain insights into originated traffic location by region. This can help you allocate computer resources to different regions according to their needs.
- Gain insights into the client, server responses on the server. This helps you identify errors in the server.
- Gain insights into network traffic for the frontend and backend systems of your server.
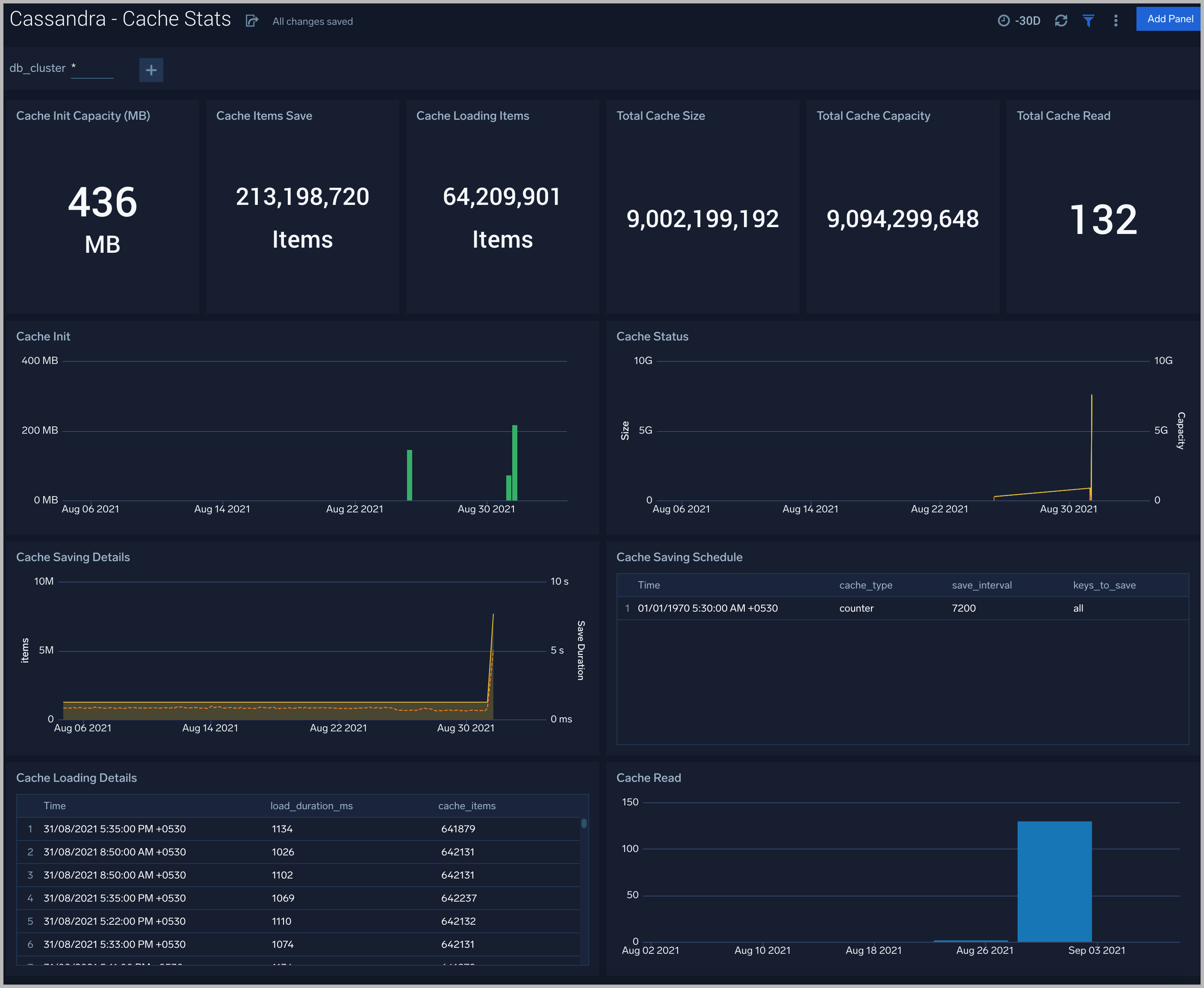
Cache Stats
The Cassandra - Cache Stats dashboard provides insight into the database cache status, schedule, and items.
Use this dashboard to:
- Monitor Cache performance.
- Identify Cache usage statistics.
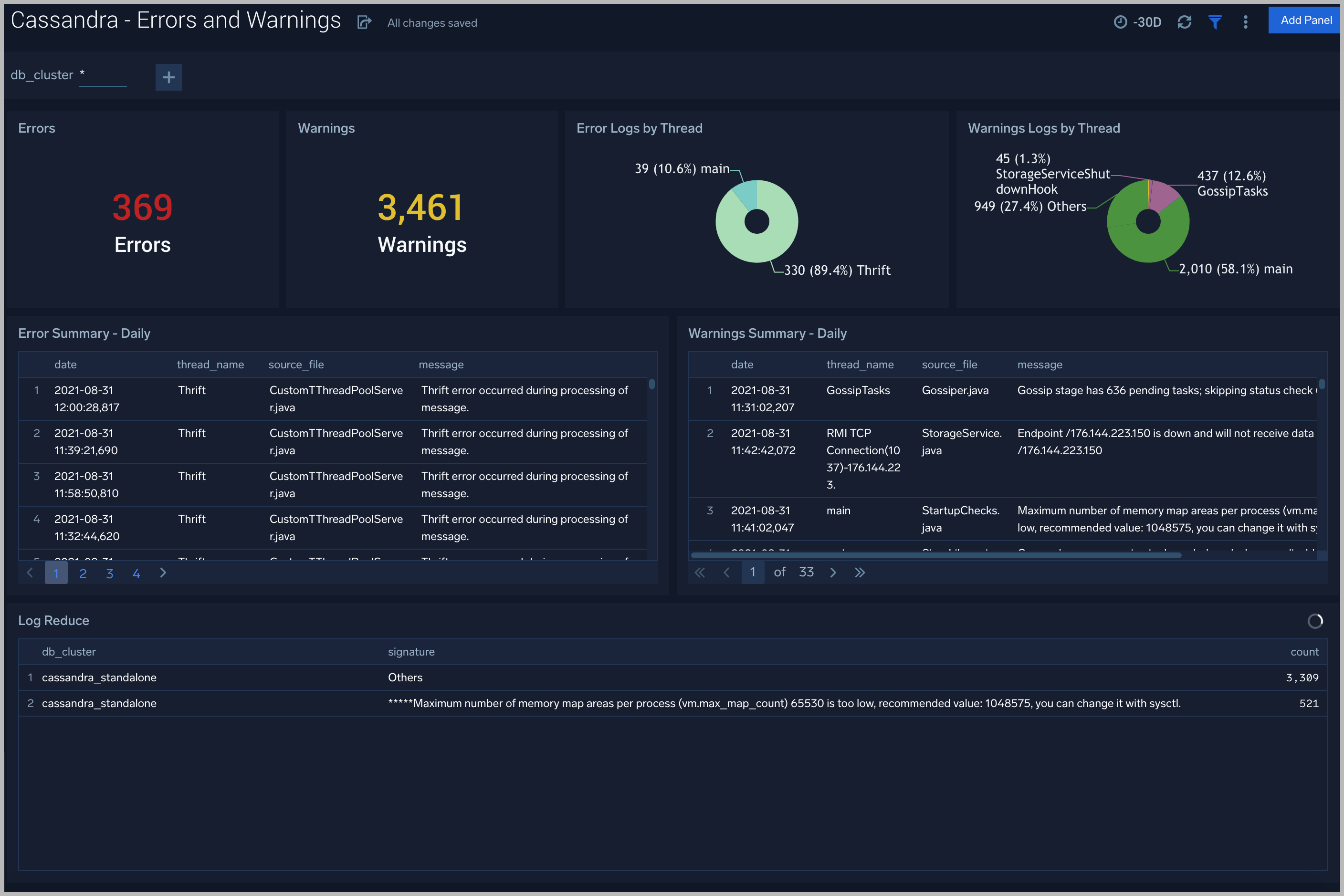
Errors and Warnings
The Cassandra - Errors and Warnings dashboard provides details of the database errors and warnings.
Use this dashboard to:
- Review errors and warnings generated by the server.
- Review the Threads errors and warning events.
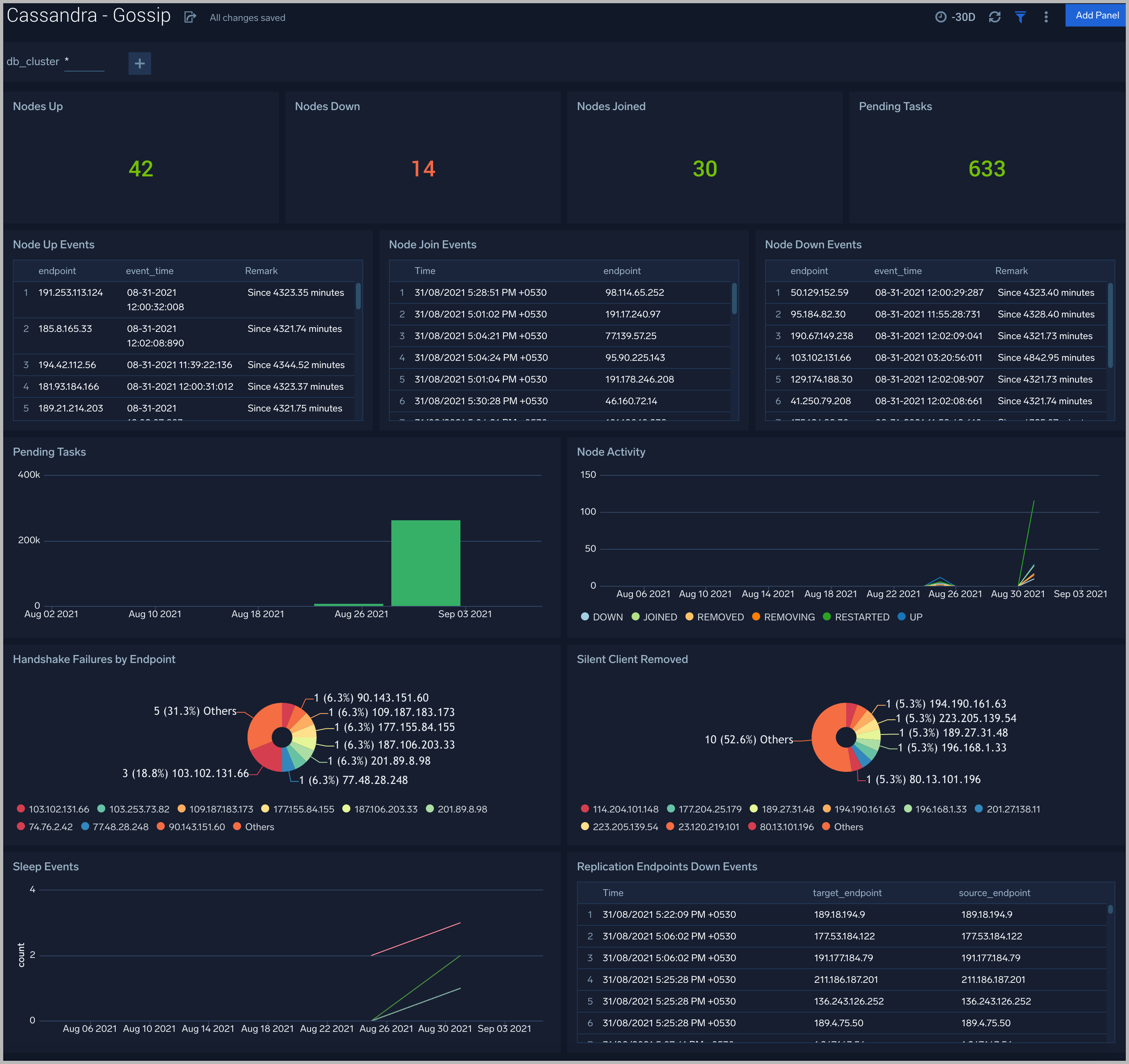
Gossip
The Cassandra - Gossip dashboard provides details about communication between various cassandra nodes.
Use this dashboard to:
- Determine nodes with errors resulting in failures.
- Review the node activity and pending tasks.
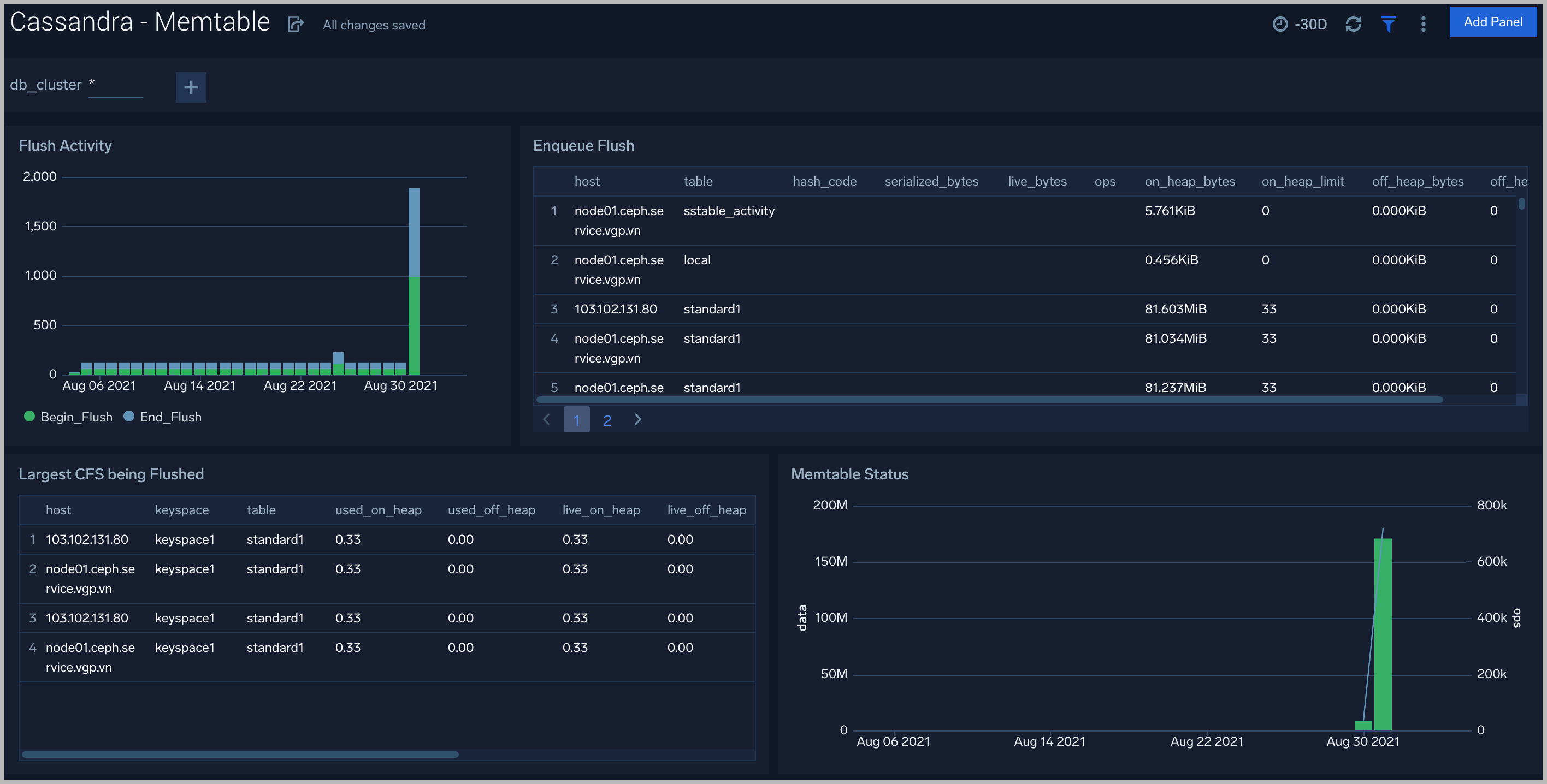
Memtable
The Cassandra - Memtable dashboard provides insights into memtable statistics.
Use this dashboard to:
- Review flush activity and memtable status.
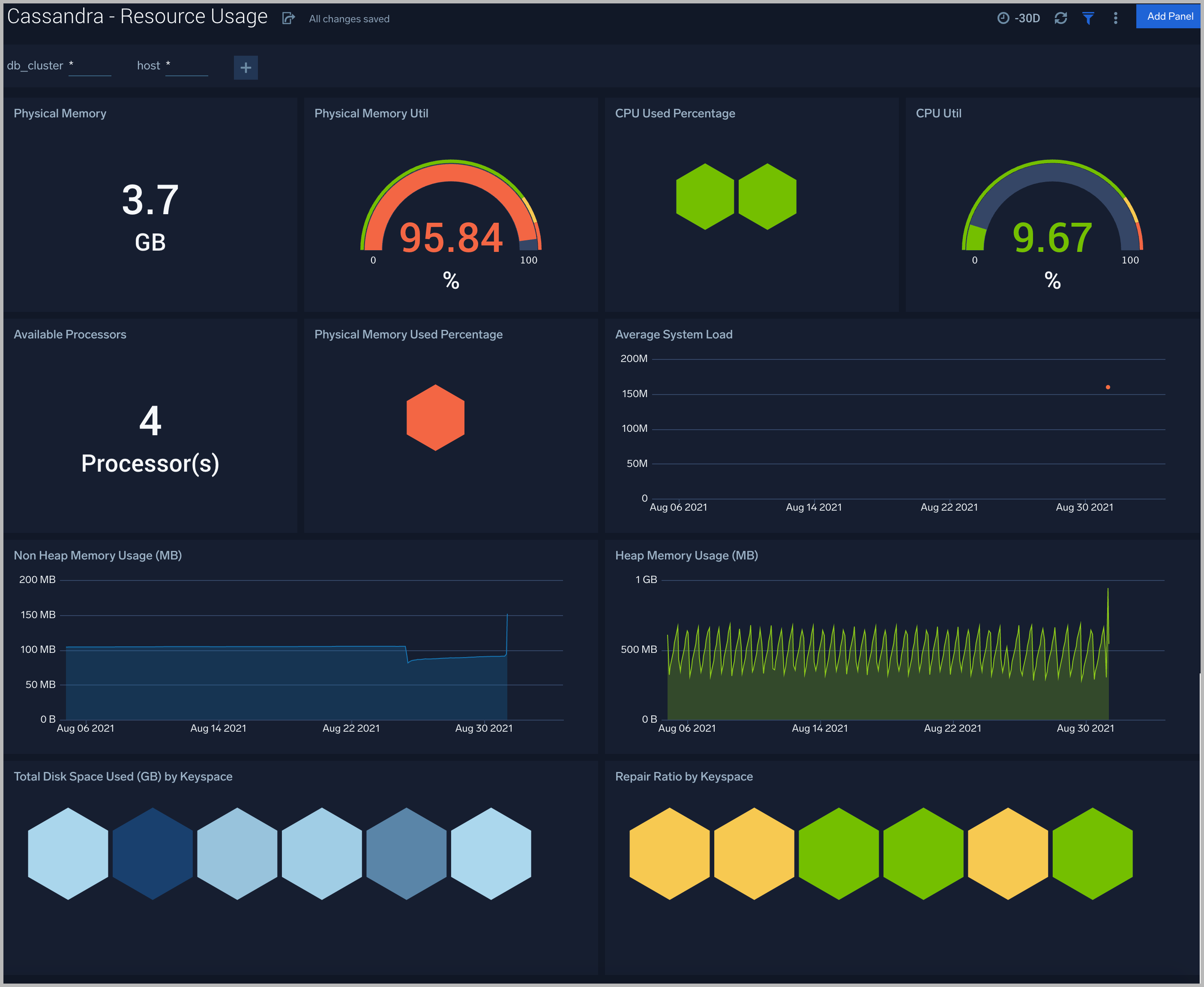
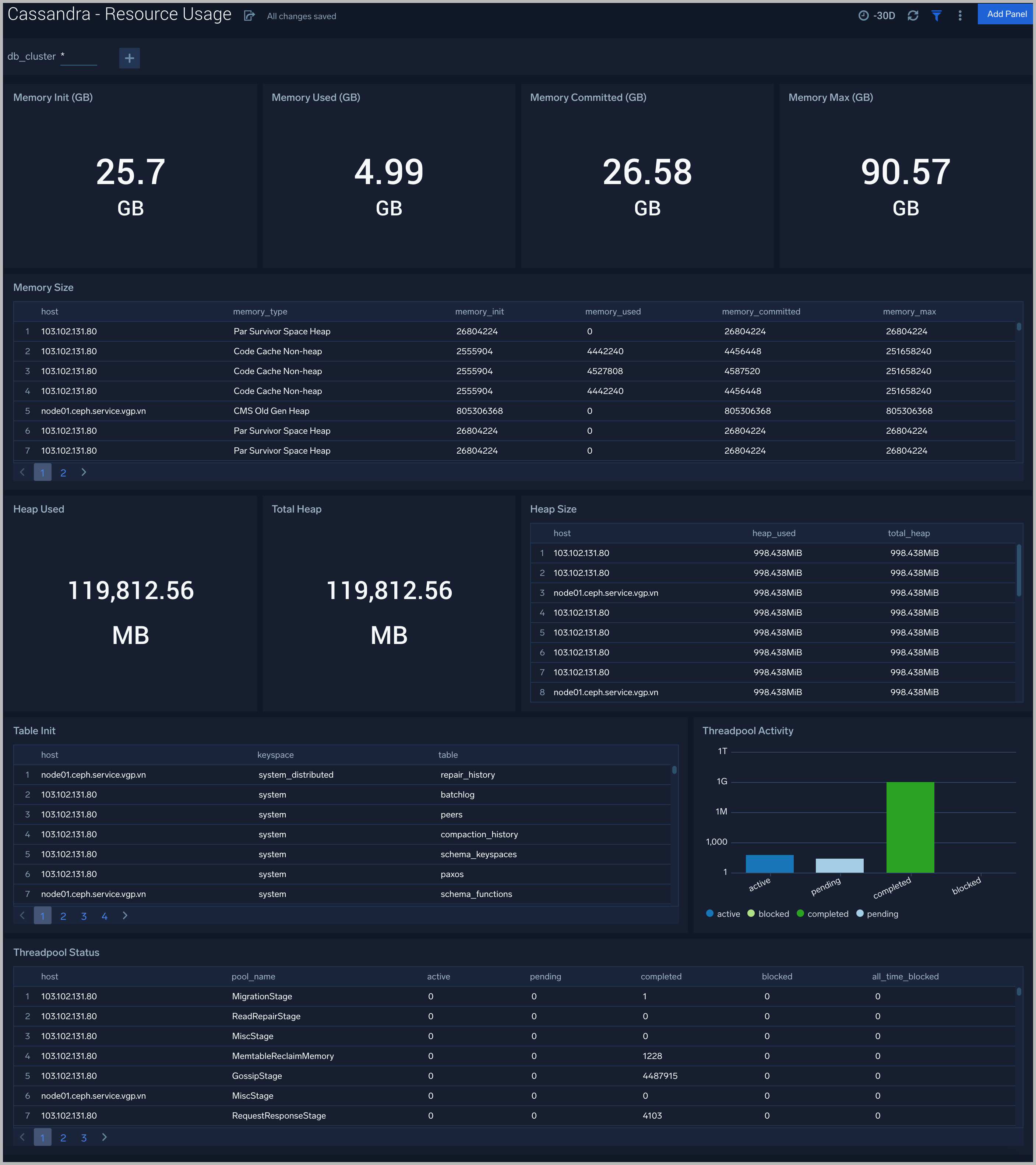
Resource Usage
The Cassandra - Resource Usage dashboard provides details of resource utilization across Cassandra clusters.
Use this dashboard to:
- Identify resource utilization. This can help you to determine whether are resources over- or under-allocated.
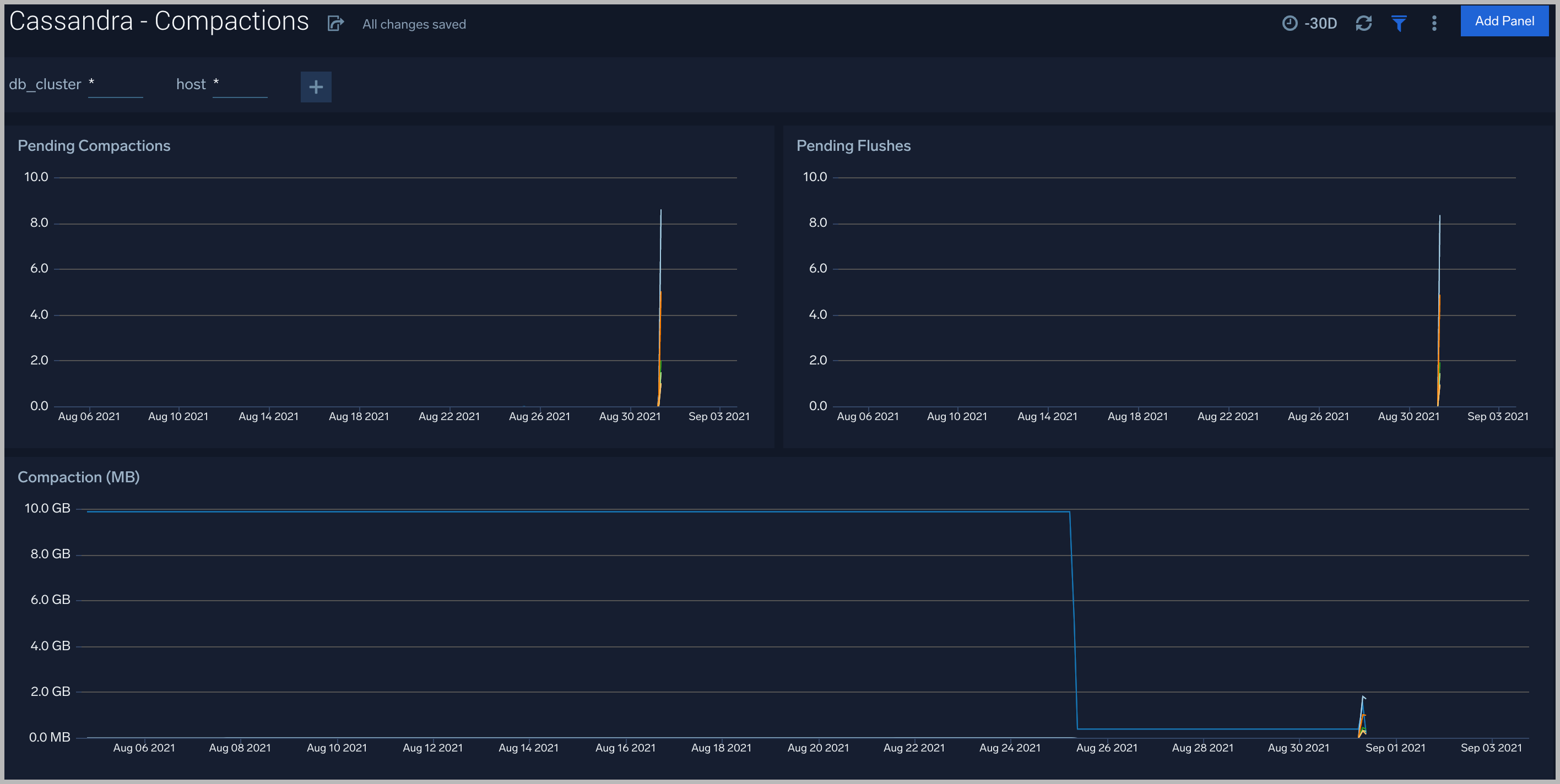
Compactions
The Cassandra - Compactions dashboard provides details of compactions.
Use this dashboard to:
- Review pending/completed compactions and flushes.
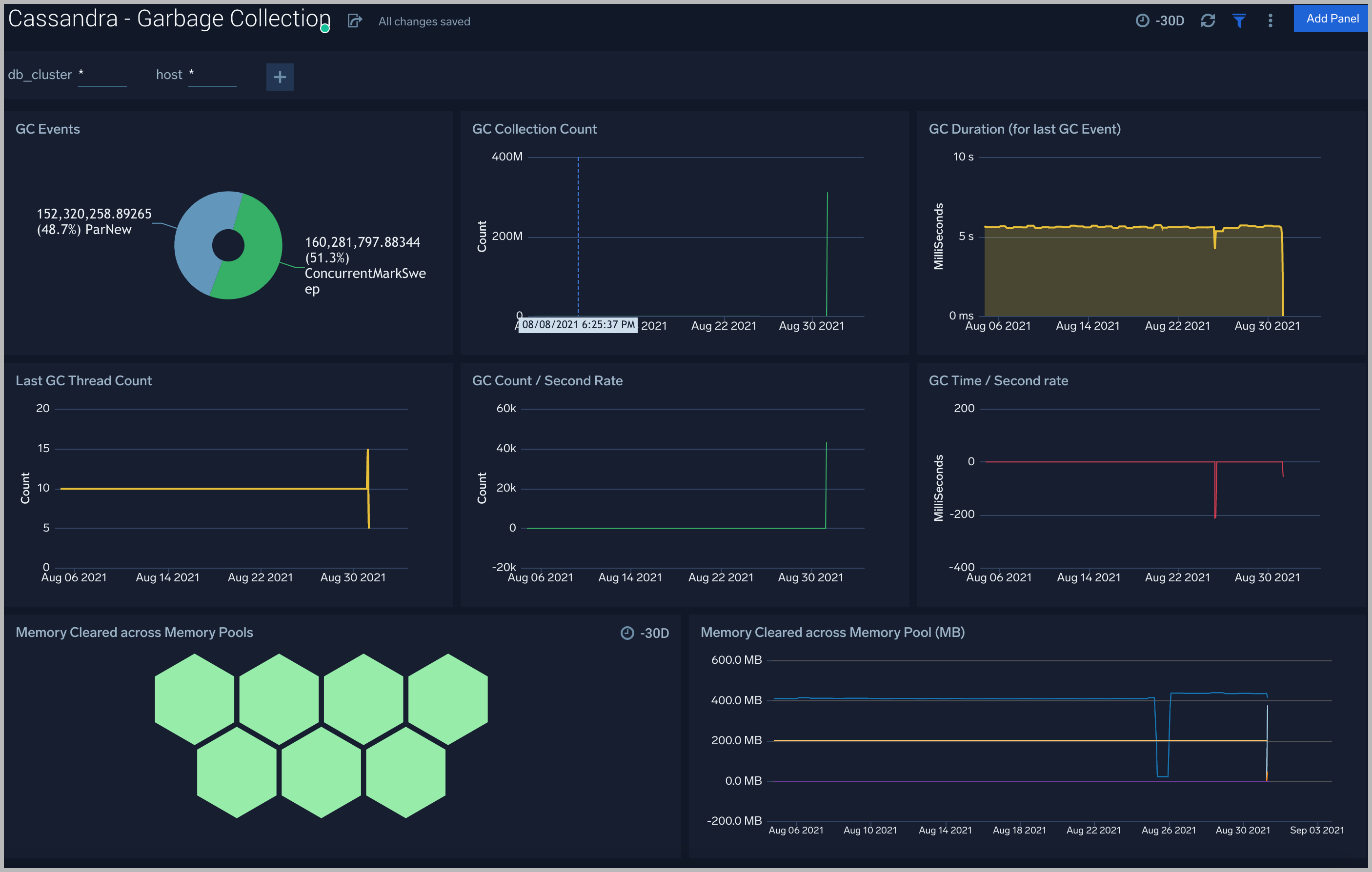
Garbage Collection
The Cassandra - Garbage Collection dashboard shows key Garbage Collector statistics like the duration of the last GC run, objects collected, threads used, and memory cleared in the last GC run.
Use this dashboard to:
- Understand the garbage collection time. If the time keeps on increasing, you may have more CPU usage.
- Understand the amount of memory cleared by garbage collectors across memory pools and its impact on the Heap memory.
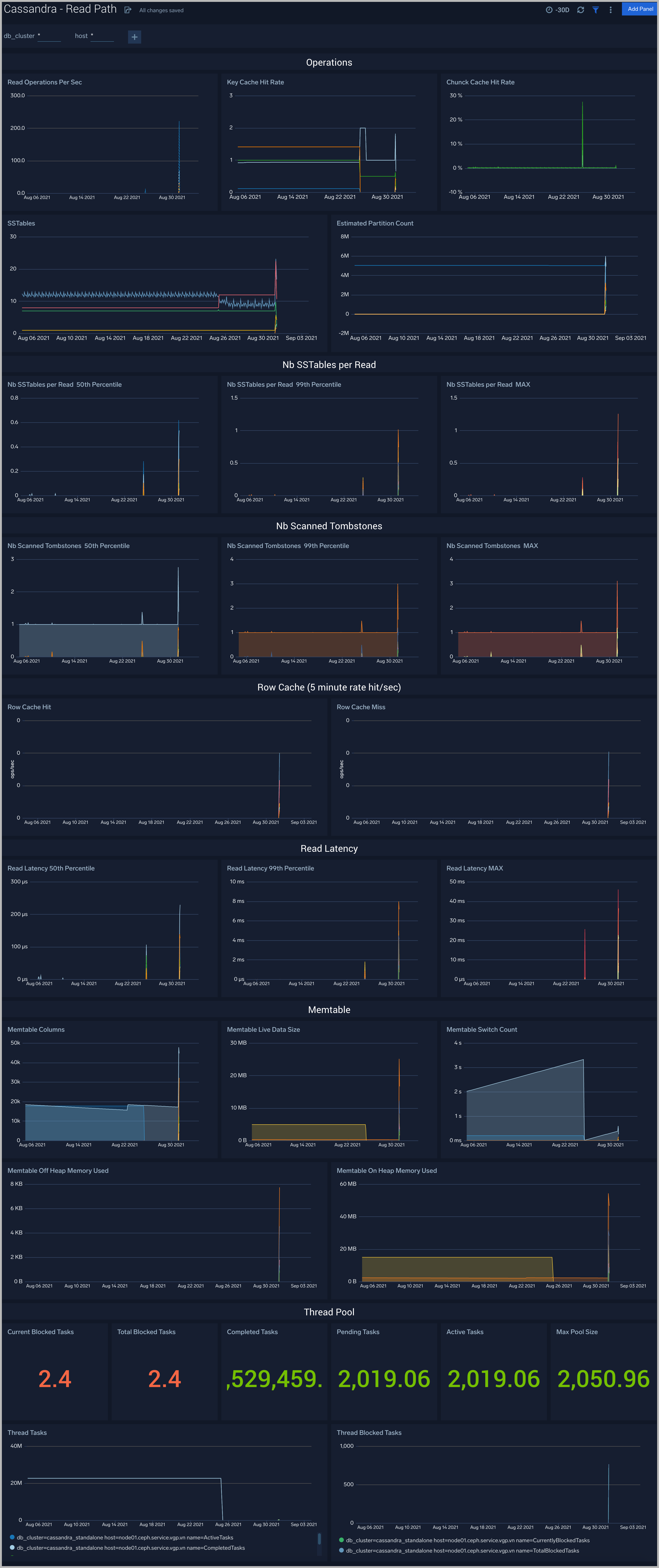
Read Path
The Cassandra - Read Path dashboard shows read operation statistics.
Use this dashboard to:
- Gather insights into read operations, cache statistics, Tombstone, and SSTTables summary.
- Review thread pool and memtable usage for read operations.
Resource Usage Logs
The Cassandra - Resource Usage Logs dashboard provides details of resource utilization across Cassandra clusters.
Use this dashboard to:
- Identify resource utilization. This can help you to determine resources over or under allocation.
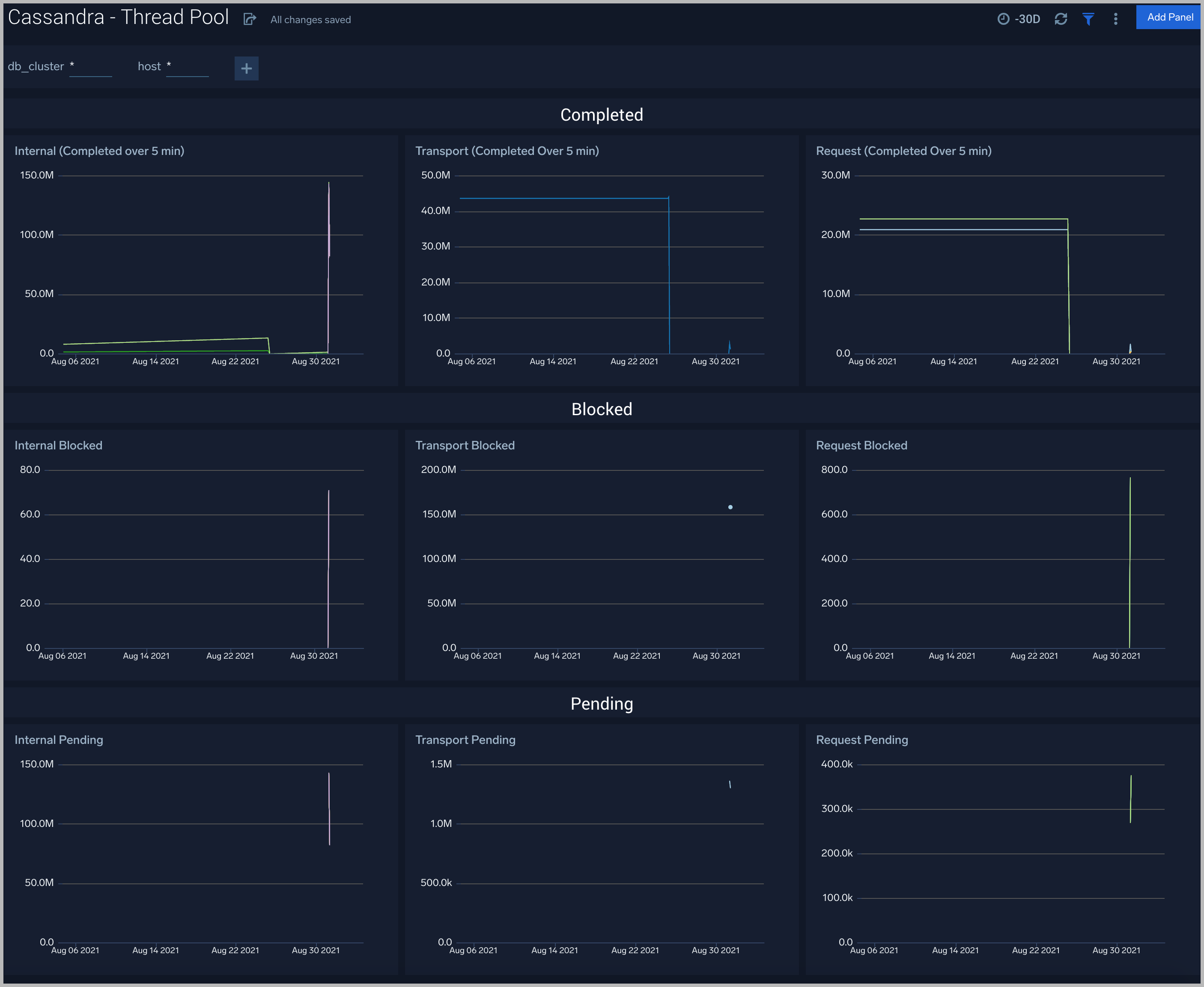
Thread Pool
The Cassandra - Thread Pool dashboard shows thread pool statistics.
Use this dashboard to:
- Review thread pool usage and statistics for different kinds of operations.
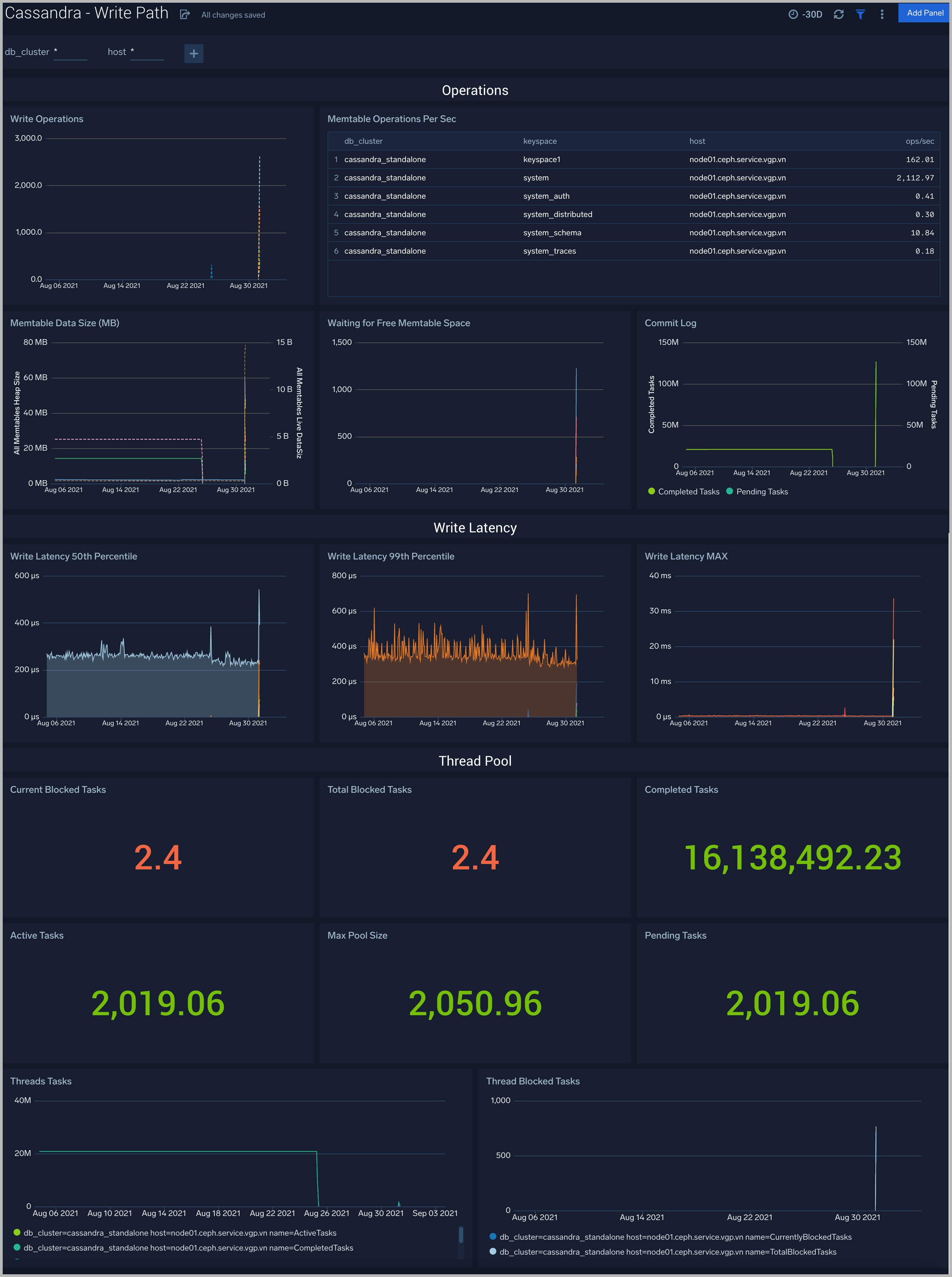
Write Path
The Cassandra - Write Path dashboard shows write operation statistics.
Use this dashboard to:
- Gather insights into write operations, cache statistics, Tombstone, and SSTTables summary.
- Review thread pool and memtable usage for write operations.
Cassandra Alerts
Sumo Logic has provided out-of-the-box alerts available via Sumo Logic monitors to help you quickly determine if the Cassandra cluster is available and performing as expected.
| Alert Name | Alert Description | Alert Condition | Recover Condition |
|---|---|---|---|
| Cassandra - Increase in Authentication Failures | This alert fires when there is an increase of Cassandra authentication failures. | >5 | <= 5 |
| Cassandra - Cache Hit Rate below 85 Percent | This alert fires when the cache key hit rate is below 85%. | <85 | >= 85 |
| Cassandra - High Commitlog Pending Tasks | This alert fires when there are more than 15 Commitlog tasks that are pending. | >15 | <= 15 |
| Cassandra - High Number of Compaction Executor Blocked Tasks | This alert fires when there are more than 15 compaction executor tasks blocked for more than 5 minutes. | >15 | <= 15 |
| Cassandra - Compaction Task Pending | This alert fires when there are many Cassandra compaction tasks that are pending. You might need to increase I/O capacity by adding nodes to the cluster. | >100 | <= 100 |
| Cassandra - High Number of Flush Writer Blocked Tasks | This alert fires when there is a high number of flush writer tasks which are blocked. | >15 | <= 15 |
| Cassandra - Many Compaction Tasks Are Pending | Many Cassandra compaction tasks are pending | >100 | <= 100 |
| Cassandra - Node Down | This alert fires when one or more Cassandra nodes are down | >0 | <= 0 |
| Cassandra - Blocked Repair Tasks | This alert fires when the repair tasks are blocked | >2 | <= 2 |
| Cassandra - Repair Tasks Pending | This alert fires when repair tasks are pending. | >2 | <= 2 |
| Cassandra - High Tombstone Scanning | This alert fires when tombstone scanning is very high (>1000 99th Percentile) in queries. | >1000 | <= 1000 |