Monitor Kubernetes Effectively
This page provides insights for effectively monitoring your Kubernetes environment with Sumo Logic, and is organized according to the individual areas of the Kubernetes architecture.
Critical areas to monitor
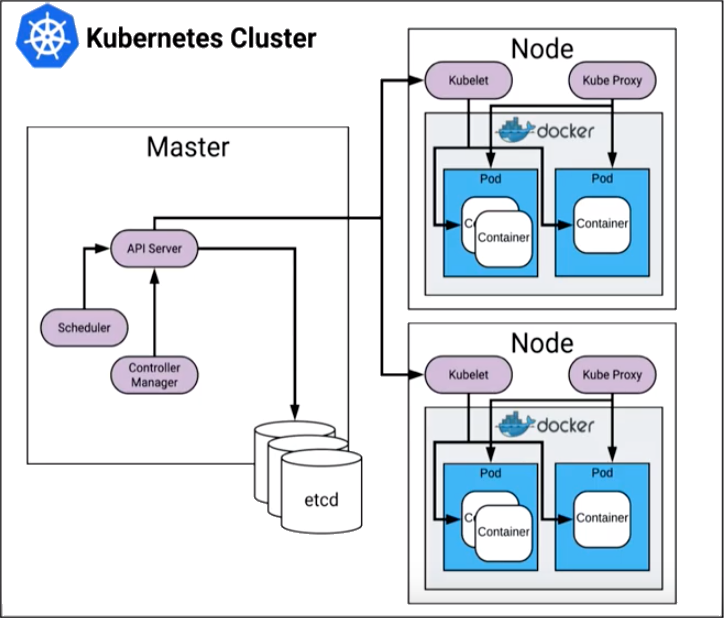
The critical areas for monitoring in Kubernetes include the control plane, individual nodes, and pods. The following illustration provides a high-level view of the Kubernetes cluster architecture.
Control Plane
The Kubernetes control plane manages how Kubernetes communicates with your cluster. The various parts of the control plane work together in managing the health and performance of a cluster. The control plane consists of the API server, etcd, controller manager, and scheduler. Each part of the control plane has specific areas that should be monitored for the optimum health and performance of your cluster.
API Server - kube-apiserver
The API server is the front door to Kubernetes. Any changes you make in the environment are communicated through the API server. The API server uses all your resources to commit the changes inside the cluster. For the kube-apiserver, you should monitor the following:
- API server latency
- Requests per minute (RPM)
- Threshold issues with etcd
ectd
The ectd of the control plane is a value store that Kubernetes uses this for storing all of the desired states for the cluster. Changes in the cluster are compared to the desired state to determine the necessary response. For ectd, you should monitor the following:
- Leader changes
- Quorum - if quorum is lost, etcd falls into a read-only state and you can't make changes to the API or get new state coming back from your cluster
- Disk space - if you lose your backup for etcd you may lose all the state for the entire cluster
Controller Manager
The controller manager is responsible for continually coalescing the running state of the cluster versus the desired state. The controller manager monitors all changes made to the API server to see if the changes are in alignment with the desired state of the cluster, and is in constant contact with the cloud provider. The controller manager checks to see if all nodes are running and that there are enough pods; continually iterating to make sure the cluster maintains the desired state. For the controller manager, you should monitor:
- End-to-end scheduling latency
- Cloud provider latency
- Failed requests to your cloud provider
Scheduler - kube-scheduler
The scheduler is responsible for scheduling the individual pods on the nodes. In order to schedule a pod, the scheduler compares the available resources with resource requests, as well as the availability of individual nodes and new nodes that are coming online due to scaling. For the scheduler, you should monitor:
- Pods that fail to schedule
- Requests, quota limits, anti-affinity
- Bin packing - the number of pods that can fit on an individual node
Nodes
A node is a worker machine in a Kubernetes cluster that serves as a delivery vehicle for your applications. Nodes can be virtual machines (VMs) or physical machines. Nodes are essentially bare-bones servers. Like any other server, you should monitor the following on each node:
- CPU
- Memory consumption
- System load
- File system activity
- Network activity
Each node is managed by the cluster and contains the services necessary to run pods. Node services include kubelet and kube-proxy.
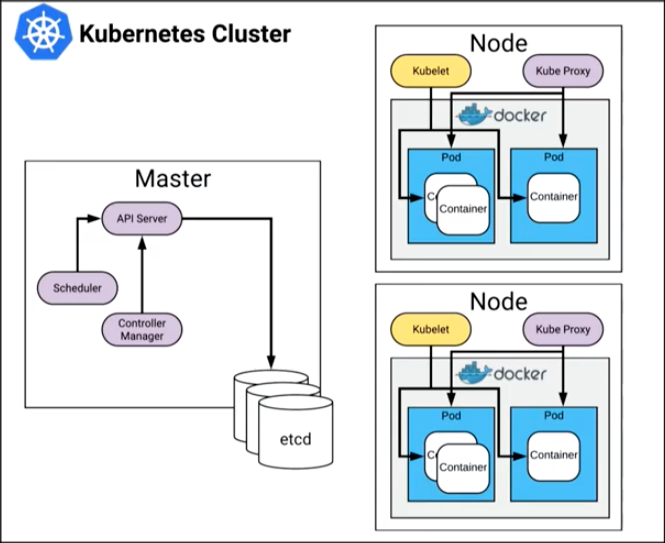
Kubelet
The kubelet daemon runs on each individual node and monitors the health of the containers on the node, interacting with the container manager. The container manager can be Docker, rkt (pronounced Rocket), or any other Open Source container manager that is supported by Kubernetes.
For the kubelet, you should monitor the container manager which is itself a monitoring service.
Kube Proxy - kube-proxy
The kube-proxy is a network proxy that runs on each node in your cluster. The kube-proxy maintains network rules on nodes that facilitate network communication to the pods from network sessions inside or outside of the cluster. For the kube proxy, you should monitor:
- Network traffic load
- Cluster DNS
- Service cluster IPs and ports
Pods
Pods reside on a given node, and a container can contain several pods. For pods, you should monitor:
- Scheduler health for individual pods - so they don't get stuck in a restart loop
- Pod health - availability, resource consumption, and performance
Kubernetes logs and metrics
Sumo Logic utilizes the following Open Source applications to provide insights into logs and metrics in your Kubernetes environment:
- FluentD, an Open Source collector, is used to collect logs from the Kubernetes cluster, then forwards them to Sumo Logic. This includes cluster and container orchestration logs, as well as logs generated by apps on your pods.
- Prometheus, an Open Source monitoring tool, is used to collect metrics that provide data on the cluster, node, and pod level.
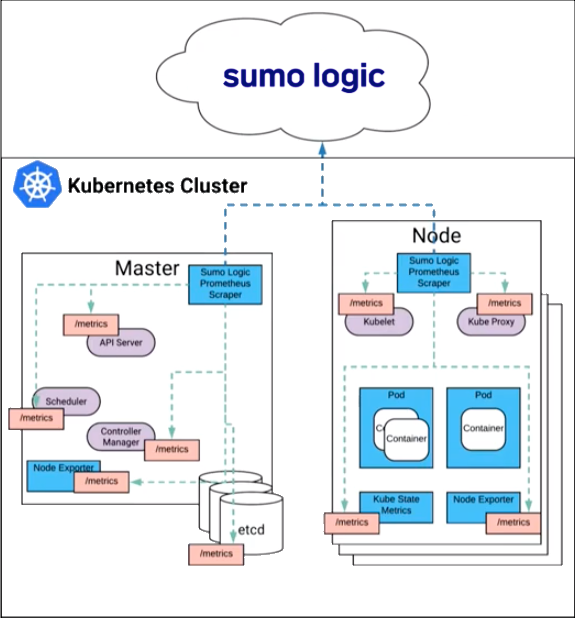
Metrics rich monitoring
Sumo Logic provides scraper utility that collects Prometheus formatted metrics from exporters. The metrics are then enriched with metadata and sent to Sumo Logic via HTTP. Sumo Logic Kubernetes apps show Prometheus format metrics in graphic display dashboards for intuitive analysis.
How Kubernetes exposes metrics
- Exporters expose metrics on a particular port and endpoint.
- Node exporter can be run to expose node metrics, such as CPU and memory utilization which can be used to monitor the health of your nodes.
- Kube State add-on exposes cluster level state information.